 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Simple and Efficient Task-Adaptive Pre-training for Text Classification
Sep 26, 2022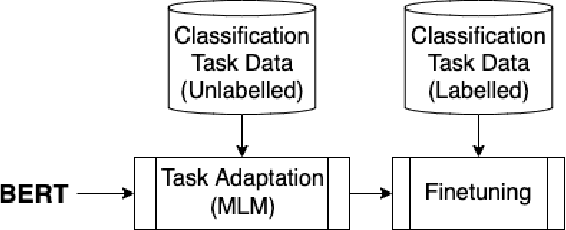

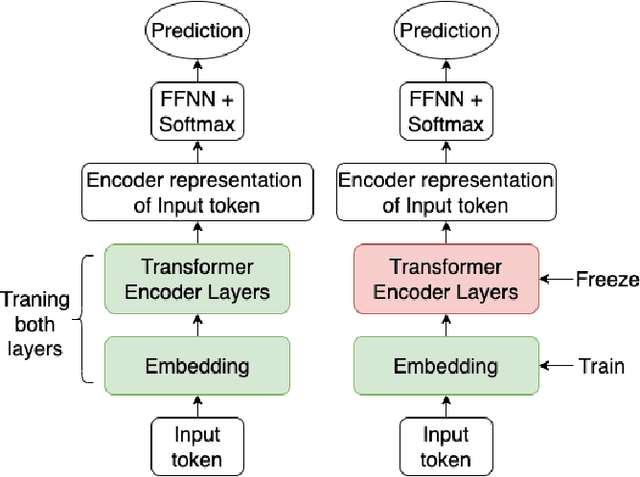
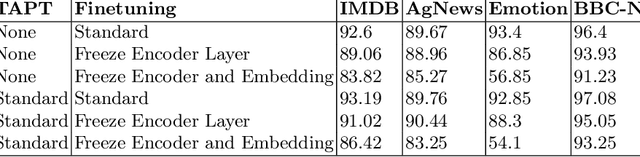
Language models are pre-trained using large corpora of generic data like book corpus, common crawl and Wikipedia, which is essential for the model to understand the linguistic characteristics of the language. New studies suggest using Domain Adaptive Pre-training (DAPT) and Task-Adaptive Pre-training (TAPT) as an intermediate step before the final finetuning task. This step helps cover the target domain vocabulary and improves the model performance on the downstream task. In this work, we study the impact of training only the embedding layer on the model's performance during TAPT and task-specific finetuning. Based on our study, we propose a simple approach to make the intermediate step of TAPT for BERT-based models more efficient by performing selective pre-training of BERT layers. We show that training only the BERT embedding layer during TAPT is sufficient to adapt to the vocabulary of the target domain and achieve comparable performance. Our approach is computationally efficient, with 78\% fewer parameters trained during TAPT. The proposed embedding layer finetuning approach can also be an efficient domain adaptation technique.
On Sensitivity of Deep Learning Based Text Classification Algorithms to Practical Input Perturbations
Jan 23, 2022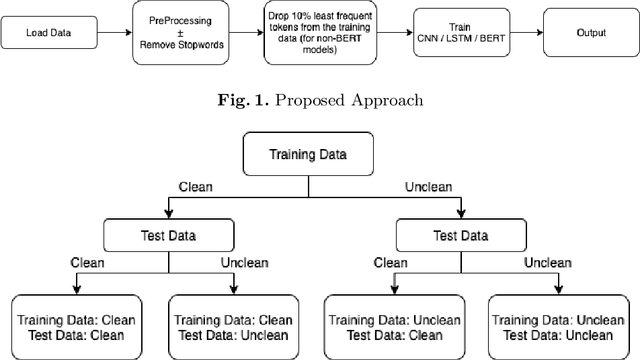
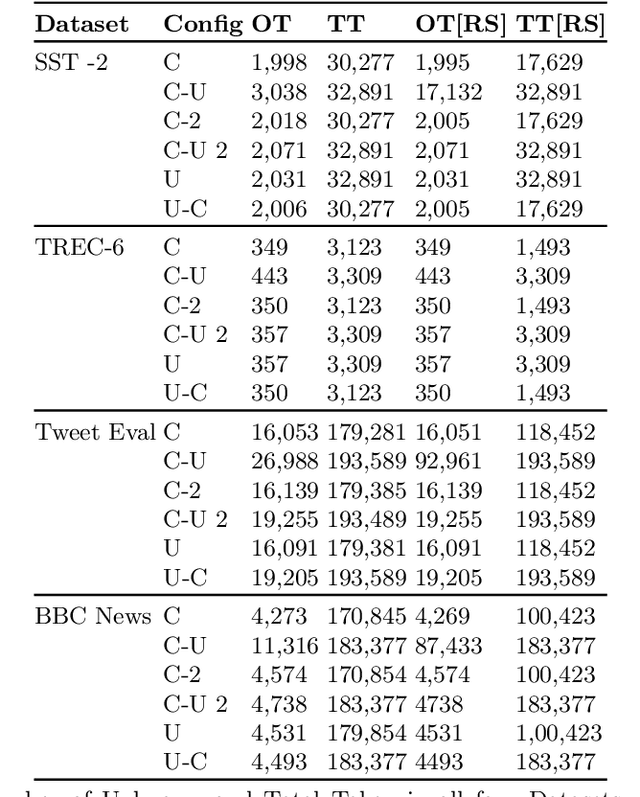
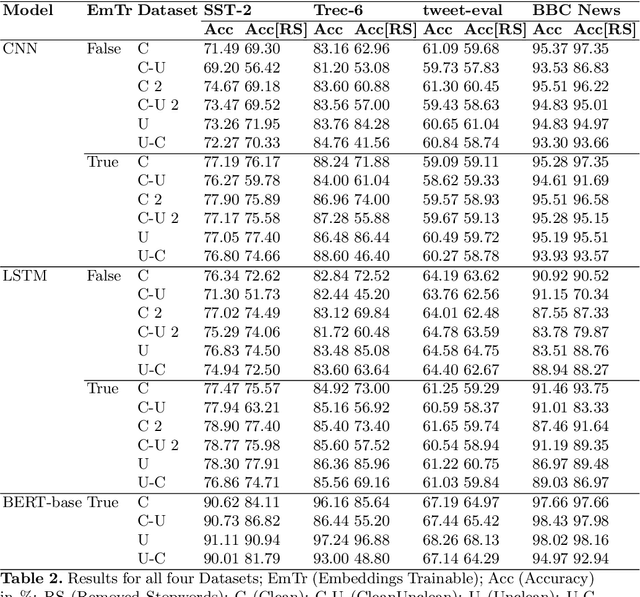
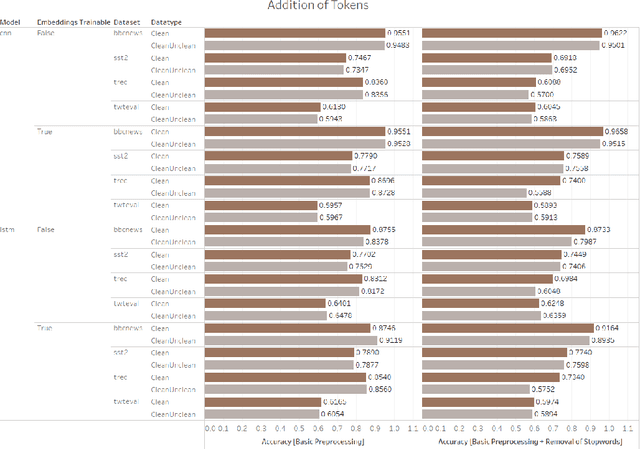
Text classification is a fundamental Natural Language Processing task that has a wide variety of applications, where deep learning approaches have produced state-of-the-art results. While these models have been heavily criticized for their black-box nature, their robustness to slight perturbations in input text has been a matter of concern. In this work, we carry out a data-focused study evaluating the impact of systematic practical perturbations on the performance of the deep learning based text classification models like CNN, LSTM, and BERT-based algorithms. The perturbations are induced by the addition and removal of unwanted tokens like punctuation and stop-words that are minimally associated with the final performance of the model. We show that these deep learning approaches including BERT are sensitive to such legitimate input perturbations on four standard benchmark datasets SST2, TREC-6, BBC News, and tweet_eval. We observe that BERT is more susceptible to the removal of tokens as compared to the addition of tokens. Moreover, LSTM is slightly more sensitive to input perturbations as compared to CNN based model. The work also serves as a practical guide to assessing the impact of discrepancies in train-test conditions on the final performance of models.