 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Musical Characteristics of National Anthems in Relation to Global Indices
Apr 04, 2024
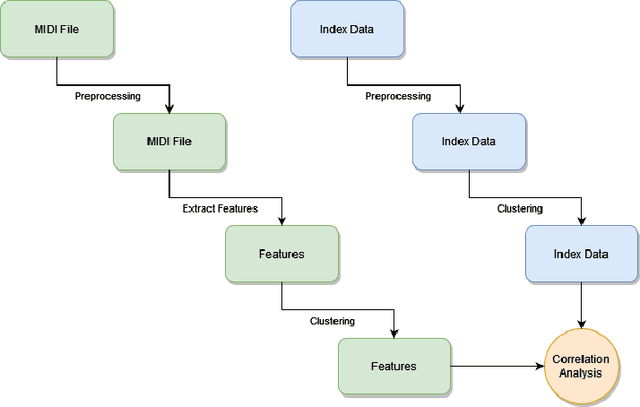
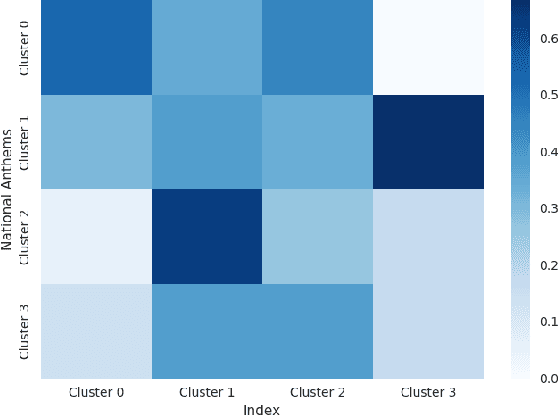
Music plays a huge part in shaping peoples' psychology and behavioral patterns. This paper investigates the connection between national anthems and different global indices with computational music analysis and statistical correlation analysis. We analyze national anthem musical data to determine whether certain musical characteristics are associated with peace, happiness, suicide rate, crime rate, etc. To achieve this, we collect national anthems from 169 countries and use computational music analysis techniques to extract pitch, tempo, beat, and other pertinent audio features. We then compare these musical characteristics with data on different global indices to ascertain whether a significant correlation exists. Our findings indicate that there may be a correlation between the musical characteristics of national anthems and the indices we investigated. The implications of our findings for music psychology and policymakers interested in promoting social well-being are discussed. This paper emphasizes the potential of musical data analysis in social research and offers a novel perspective on the relationship between music and social indices. The source code and data are made open-access for reproducibility and future research endeavors. It can be accessed at http://bit.ly/na_code.
Optical Text Recognition in Nepali and Bengali: A Transformer-based Approach
Apr 03, 2024



Efforts on the research and development of OCR systems for Low-Resource Languages are relatively new. Low-resource languages have little training data available for training Machine Translation systems or other systems. Even though a vast amount of text has been digitized and made available on the internet the text is still in PDF and Image format, which are not instantly accessible. This paper discusses text recognition for two scripts: Bengali and Nepali; there are about 300 and 40 million Bengali and Nepali speakers respectively. In this study, using encoder-decoder transformers, a model was developed, and its efficacy was assessed using a collection of optical text images, both handwritten and printed. The results signify that the suggested technique corresponds with current approaches and achieves high precision in recognizing text in Bengali and Nepali. This study can pave the way for the advanced and accessible study of linguistics in South East Asia.
Obfuscated Malware Detection: Investigating Real-world Scenarios through Memory Analysis
Apr 03, 2024



In the era of the internet and smart devices, the detection of malware has become crucial for system security. Malware authors increasingly employ obfuscation techniques to evade advanced security solutions, making it challenging to detect and eliminate threats. Obfuscated malware, adept at hiding itself, poses a significant risk to various platforms, including computers, mobile devices, and IoT devices. Conventional methods like heuristic-based or signature-based systems struggle against this type of malware, as it leaves no discernible traces on the system. In this research, we propose a simple and cost-effective obfuscated malware detection system through memory dump analysis, utilizing diverse machine-learning algorithms. The study focuses on the CIC-MalMem-2022 dataset, designed to simulate real-world scenarios and assess memory-based obfuscated malware detection. We evaluate the effectiveness of machine learning algorithms, such as decision trees, ensemble methods, and neural networks, in detecting obfuscated malware within memory dumps. Our analysis spans multiple malware categories, providing insights into algorithmic strengths and limitations. By offering a comprehensive assessment of machine learning algorithms for obfuscated malware detection through memory analysis, this paper contributes to ongoing efforts to enhance cybersecurity and fortify digital ecosystems against evolving and sophisticated malware threats. The source code is made open-access for reproducibility and future research endeavours. It can be accessed at https://bit.ly/MalMemCode.