 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Identification using MFCC-Domain Support Vector Machine
Sep 25, 2010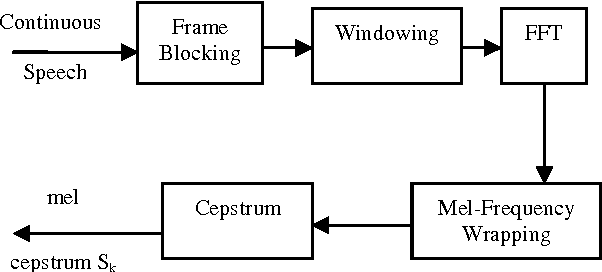
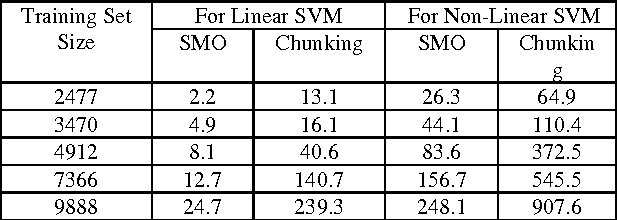
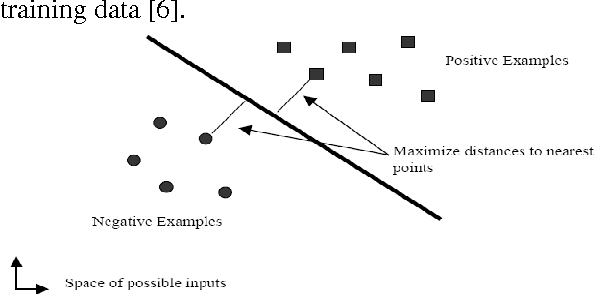
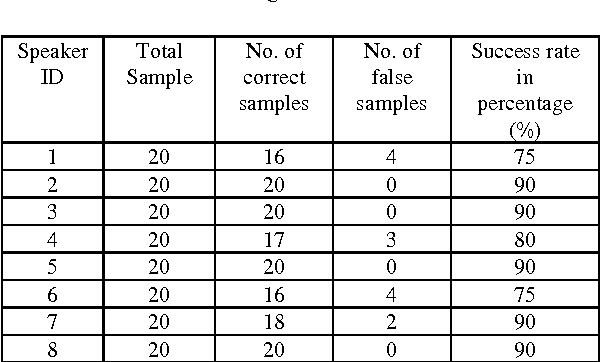
Speech recognition and speaker identification are important for authentication and verification in security purpose, but they are difficult to achieve. Speaker identification methods can be divided into text-independent and text-dependent. This paper presents a technique of text-dependent speaker identification using MFCC-domain support vector machine (SVM). In this work, melfrequency cepstrum coefficients (MFCCs) and their statistical distribution properties are used as features, which will be inputs to the neural network. This work firstly used sequential minimum optimization (SMO) learning technique for SVM that improve performance over traditional techniques Chunking, Osuna. The cepstrum coefficients representing the speaker characteristics of a speech segment are computed by nonlinear filter bank analysis and discrete cosine transform. The speaker identification ability and convergence speed of the SVMs are investigated for different combinations of features. Extensive experimental results on several samples show the effectiveness of the proposed approach.
* 5 Pages, International Journal