 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Academic Paper Generation
Dec 02, 2019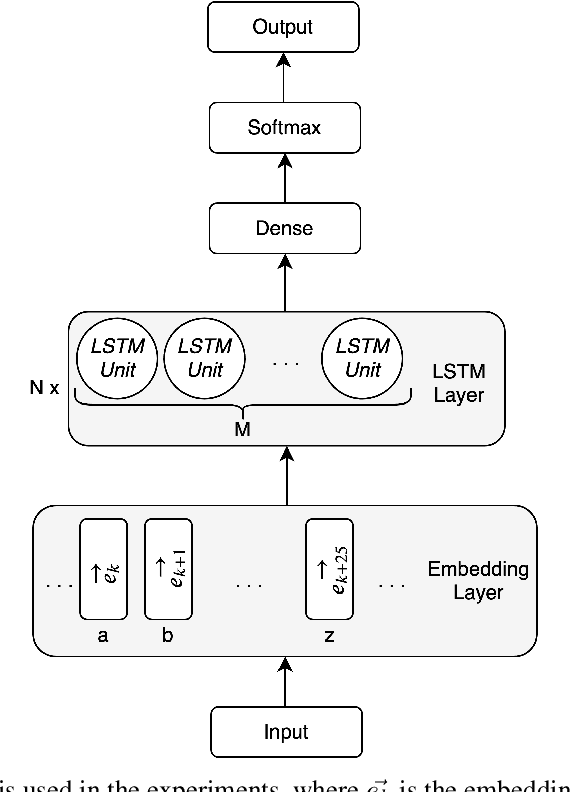
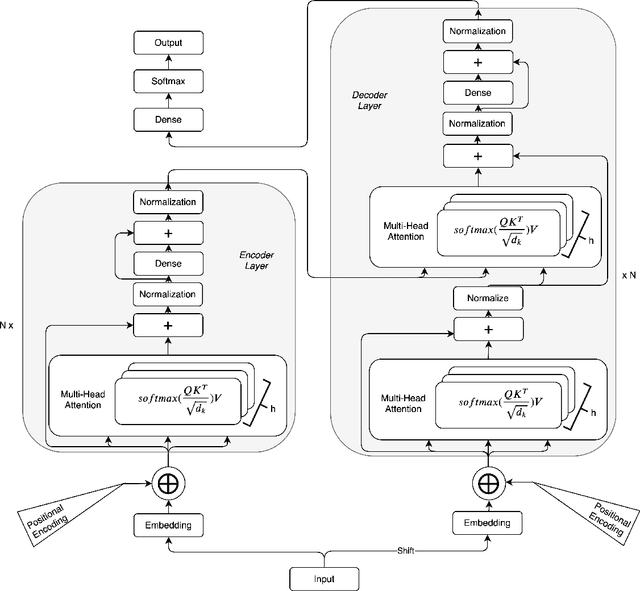
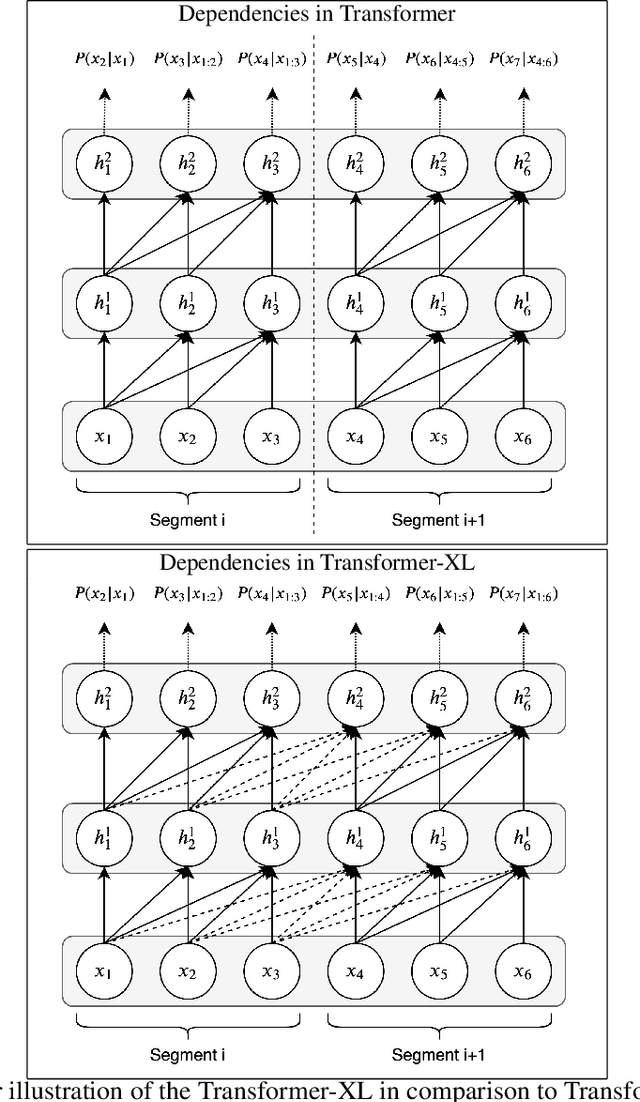
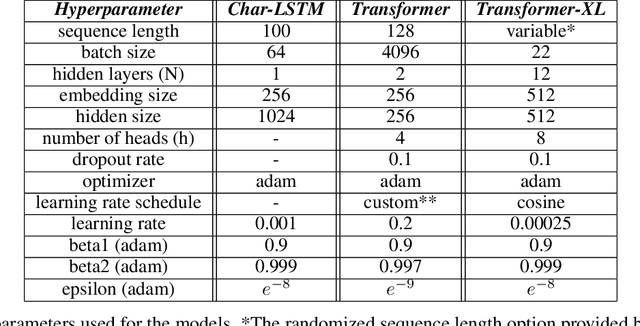
In this work, we tackle the problem of structured text generation, specifically academic paper generation in $\LaTeX{}$, inspired by the surprisingly good results of basic character-level language models. Our motivation is using more recent and advanced methods of language modeling on a more complex dataset of $\LaTeX{}$ source files to generate realistic academic papers. Our first contribution is preparing a dataset with $\LaTeX{}$ source files on recent open-source computer vision papers. Our second contribution is experimenting with recent methods of language modeling and text generation such as Transformer and Transformer-XL to generate consistent $\LaTeX{}$ code. We report cross-entropy and bits-per-character (BPC) results of the trained models, and we also discuss interesting points on some examples of the generated $\LaTeX{}$ code.