 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs For Turkish Skill Extraction
Jan 30, 2026Skill extraction is a critical component of modern recruitment systems, enabling efficient job matching, personalized recommendations, and labor market analysis. Despite Türkiye's significant role in the global workforce, Turkish, a morphologically complex language, lacks both a skill taxonomy and a dedicated skill extraction dataset, resulting in underexplored research in skill extraction for Turkish. This article seeks the answers to three research questions: 1) How can skill extraction be effectively performed for this language, in light of its low resource nature? 2)~What is the most promising model? 3) What is the impact of different Large Language Models (LLMs) and prompting strategies on skill extraction (i.e., dynamic vs. static few-shot samples, varying context information, and encouraging causal reasoning)? The article introduces the first Turkish skill extraction dataset and performance evaluations of automated skill extraction using LLMs. The manually annotated dataset contains 4,819 labeled skill spans from 327 job postings across different occupation areas. The use of LLM outperforms supervised sequence labeling when used in an end-to-end pipeline, aligning extracted spans with standardized skills in the ESCO taxonomy more effectively. The best-performing configuration, utilizing Claude Sonnet 3.7 with dynamic few-shot prompting for skill identification, embedding-based retrieval, and LLM-based reranking for skill linking, achieves an end-to-end performance of 0.56, positioning Turkish alongside similar studies in other languages, which are few in the literature. Our findings suggest that LLMs can improve skill extraction performance in low-resource settings, and we hope that our work will accelerate similar research on skill extraction for underrepresented languages.
A Comparative Study of Machine Learning Methods for Predicting the Evolution of Brain Connectivity from a Baseline Timepoint
Sep 16, 2021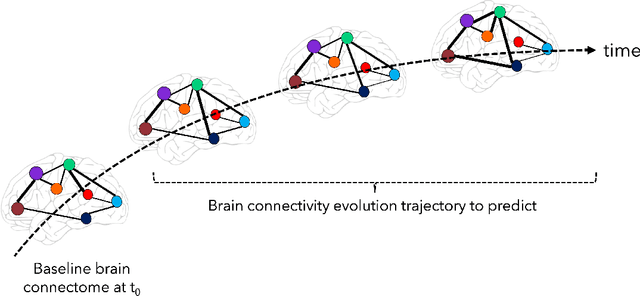
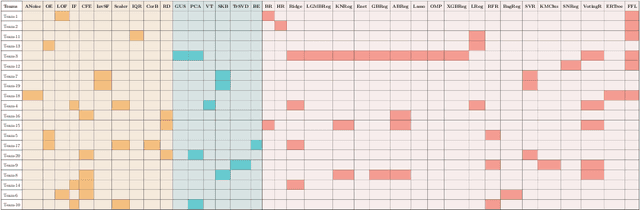
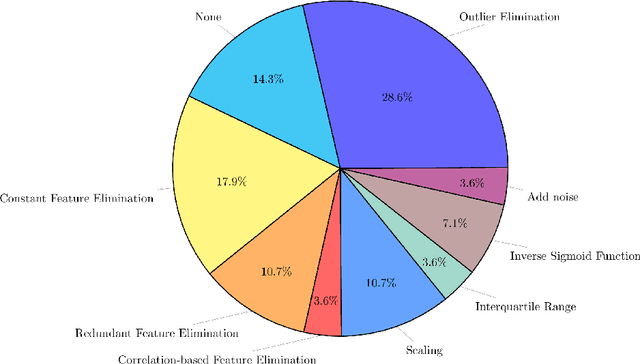
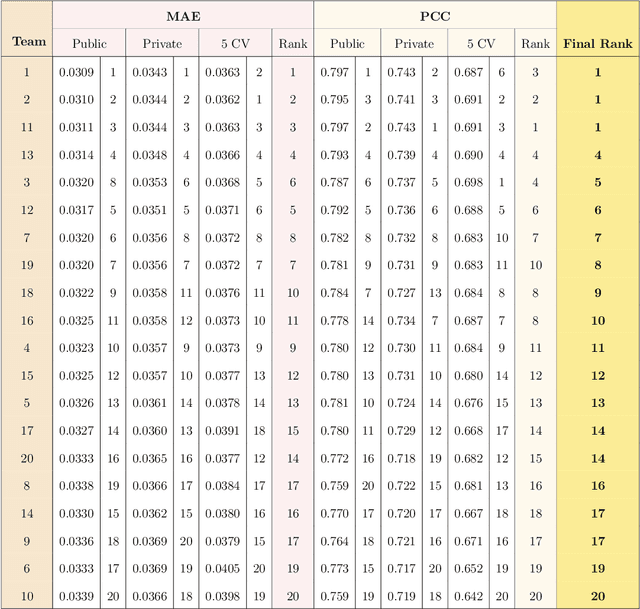
Predicting the evolution of the brain network, also called connectome, by foreseeing changes in the connectivity weights linking pairs of anatomical regions makes it possible to spot connectivity-related neurological disorders in earlier stages and detect the development of potential connectomic anomalies. Remarkably, such a challenging prediction problem remains least explored in the predictive connectomics literature. It is a known fact that machine learning (ML) methods have proven their predictive abilities in a wide variety of computer vision problems. However, ML techniques specifically tailored for the prediction of brain connectivity evolution trajectory from a single timepoint are almost absent. To fill this gap, we organized a Kaggle competition where 20 competing teams designed advanced machine learning pipelines for predicting the brain connectivity evolution from a single timepoint. The competing teams developed their ML pipelines with a combination of data pre-processing, dimensionality reduction, and learning methods. Utilizing an inclusive evaluation approach, we ranked the methods based on two complementary evaluation metrics (mean absolute error (MAE) and Pearson Correlation Coefficient (PCC)) and their performances using different training and testing data perturbation strategies (single random split and cross-validation). The final rank was calculated using the rank product for each competing team across all evaluation measures and validation strategies. In support of open science, the developed 20 ML pipelines along with the connectomic dataset are made available on GitHub. The outcomes of this competition are anticipated to lead to the further development of predictive models that can foresee the evolution of brain connectivity over time, as well as other types of networks (e.g., genetic networks).