 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtHOI: Articulated Human-Object Interaction Synthesis by 4D Reconstruction from Video Priors
Mar 04, 2026Synthesizing physically plausible articulated human-object interactions (HOI) without 3D/4D supervision remains a fundamental challenge. While recent zero-shot approaches leverage video diffusion models to synthesize human-object interactions, they are largely confined to rigid-object manipulation and lack explicit 4D geometric reasoning. To bridge this gap, we formulate articulated HOI synthesis as a 4D reconstruction problem from monocular video priors: given only a video generated by a diffusion model, we reconstruct a full 4D articulated scene without any 3D supervision. This reconstruction-based approach treats the generated 2D video as supervision for an inverse rendering problem, recovering geometrically consistent and physically plausible 4D scenes that naturally respect contact, articulation, and temporal coherence. We introduce ArtHOI, the first zero-shot framework for articulated human-object interaction synthesis via 4D reconstruction from video priors. Our key designs are: 1) Flow-based part segmentation: leveraging optical flow as a geometric cue to disentangle dynamic from static regions in monocular video; 2) Decoupled reconstruction pipeline: joint optimization of human motion and object articulation is unstable under monocular ambiguity, so we first recover object articulation, then synthesize human motion conditioned on the reconstructed object states. ArtHOI bridges video-based generation and geometry-aware reconstruction, producing interactions that are both semantically aligned and physically grounded. Across diverse articulated scenes (e.g., opening fridges, cabinets, microwaves), ArtHOI significantly outperforms prior methods in contact accuracy, penetration reduction, and articulation fidelity, extending zero-shot interaction synthesis beyond rigid manipulation through reconstruction-informed synthesis.
Through the Lens of Contrast: Self-Improving Visual Reasoning in VLMs
Mar 03, 2026Reasoning has emerged as a key capability of large language models. In linguistic tasks, this capability can be enhanced by self-improving techniques that refine reasoning paths for subsequent finetuning. However, extending these language-based self-improving approaches to vision language models (VLMs) presents a unique challenge:~visual hallucinations in reasoning paths cannot be effectively verified or rectified. Our solution starts with a key observation about visual contrast: when presented with a contrastive VQA pair, i.e., two visually similar images with synonymous questions, VLMs identify relevant visual cues more precisely. Motivated by this observation, we propose Visual Contrastive Self-Taught Reasoner (VC-STaR), a novel self-improving framework that leverages visual contrast to mitigate hallucinations in model-generated rationales. We collect a diverse suite of VQA datasets, curate contrastive pairs according to multi-modal similarity, and generate rationales using VC-STaR. Consequently, we obtain a new visual reasoning dataset, VisCoR-55K, which is then used to boost the reasoning capability of various VLMs through supervised finetuning. Extensive experiments show that VC-STaR not only outperforms existing self-improving approaches but also surpasses models finetuned on the SoTA visual reasoning datasets, demonstrating that the inherent contrastive ability of VLMs can bootstrap their own visual reasoning. Project at: https://github.com/zhiyupan42/VC-STaR.
PandaPose: 3D Human Pose Lifting from a Single Image via Propagating 2D Pose Prior to 3D Anchor Space
Feb 01, 20263D human pose lifting from a single RGB image is a challenging task in 3D vision. Existing methods typically establish a direct joint-to-joint mapping from 2D to 3D poses based on 2D features. This formulation suffers from two fundamental limitations: inevitable error propagation from input predicted 2D pose to 3D predictions and inherent difficulties in handling self-occlusion cases. In this paper, we propose PandaPose, a 3D human pose lifting approach via propagating 2D pose prior to 3D anchor space as the unified intermediate representation. Specifically, our 3D anchor space comprises: (1) Joint-wise 3D anchors in the canonical coordinate system, providing accurate and robust priors to mitigate 2D pose estimation inaccuracies. (2) Depth-aware joint-wise feature lifting that hierarchically integrates depth information to resolve self-occlusion ambiguities. (3) The anchor-feature interaction decoder that incorporates 3D anchors with lifted features to generate unified anchor queries encapsulating joint-wise 3D anchor set, visual cues and geometric depth information. The anchor queries are further employed to facilitate anchor-to-joint ensemble prediction. Experiments on three well-established benchmarks (i.e., Human3.6M, MPI-INF-3DHP and 3DPW) demonstrate the superiority of our proposition. The substantial reduction in error by $14.7\%$ compared to SOTA methods on the challenging conditions of Human3.6M and qualitative comparisons further showcase the effectiveness and robustness of our approach.
BokehFlow: Depth-Free Controllable Bokeh Rendering via Flow Matching
Nov 19, 2025
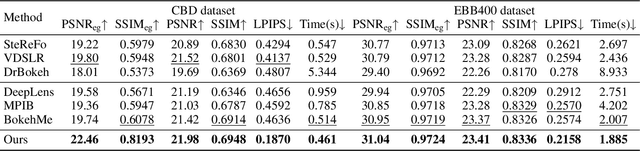
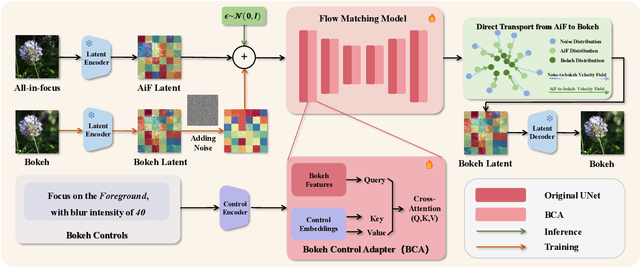
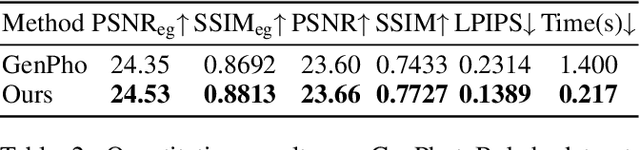
Bokeh rendering simulates the shallow depth-of-field effect in photography, enhancing visual aesthetics and guiding viewer attention to regions of interest. Although recent approaches perform well, rendering controllable bokeh without additional depth inputs remains a significant challenge. Existing classical and neural controllable methods rely on accurate depth maps, while generative approaches often struggle with limited controllability and efficiency. In this paper, we propose BokehFlow, a depth-free framework for controllable bokeh rendering based on flow matching. BokehFlow directly synthesizes photorealistic bokeh effects from all-in-focus images, eliminating the need for depth inputs. It employs a cross-attention mechanism to enable semantic control over both focus regions and blur intensity via text prompts. To support training and evaluation, we collect and synthesize four datasets. Extensive experiments demonstrate that BokehFlow achieves visually compelling bokeh effects and offers precise control, outperforming existing depth-dependent and generative methods in both rendering quality and efficiency.
Generative Photographic Control for Scene-Consistent Video Cinematic Editing
Nov 17, 2025Cinematic storytelling is profoundly shaped by the artful manipulation of photographic elements such as depth of field and exposure. These effects are crucial in conveying mood and creating aesthetic appeal. However, controlling these effects in generative video models remains highly challenging, as most existing methods are restricted to camera motion control. In this paper, we propose CineCtrl, the first video cinematic editing framework that provides fine control over professional camera parameters (e.g., bokeh, shutter speed). We introduce a decoupled cross-attention mechanism to disentangle camera motion from photographic inputs, allowing fine-grained, independent control without compromising scene consistency. To overcome the shortage of training data, we develop a comprehensive data generation strategy that leverages simulated photographic effects with a dedicated real-world collection pipeline, enabling the construction of a large-scale dataset for robust model training. Extensive experiments demonstrate that our model generates high-fidelity videos with precisely controlled, user-specified photographic camera effects.
Semi-Supervised High Dynamic Range Image Reconstructing via Bi-Level Uncertain Area Masking
Nov 17, 2025Reconstructing high dynamic range (HDR) images from low dynamic range (LDR) bursts plays an essential role in the computational photography. Impressive progress has been achieved by learning-based algorithms which require LDR-HDR image pairs. However, these pairs are hard to obtain, which motivates researchers to delve into the problem of annotation-efficient HDR image reconstructing: how to achieve comparable performance with limited HDR ground truths (GTs). This work attempts to address this problem from the view of semi-supervised learning where a teacher model generates pseudo HDR GTs for the LDR samples without GTs and a student model learns from pseudo GTs. Nevertheless, the confirmation bias, i.e., the student may learn from the artifacts in pseudo HDR GTs, presents an impediment. To remove this impediment, an uncertainty-based masking process is proposed to discard unreliable parts of pseudo GTs at both pixel and patch levels, then the trusted areas can be learned from by the student. With this novel masking process, our semi-supervised HDR reconstructing method not only outperforms previous annotation-efficient algorithms, but also achieves comparable performance with up-to-date fully-supervised methods by using only 6.7% HDR GTs.
Identity-Preserving Image-to-Video Generation via Reward-Guided Optimization
Oct 16, 2025Recent advances in image-to-video (I2V) generation have achieved remarkable progress in synthesizing high-quality, temporally coherent videos from static images. Among all the applications of I2V, human-centric video generation includes a large portion. However, existing I2V models encounter difficulties in maintaining identity consistency between the input human image and the generated video, especially when the person in the video exhibits significant expression changes and movements. This issue becomes critical when the human face occupies merely a small fraction of the image. Since humans are highly sensitive to identity variations, this poses a critical yet under-explored challenge in I2V generation. In this paper, we propose Identity-Preserving Reward-guided Optimization (IPRO), a novel video diffusion framework based on reinforcement learning to enhance identity preservation. Instead of introducing auxiliary modules or altering model architectures, our approach introduces a direct and effective tuning algorithm that optimizes diffusion models using a face identity scorer. To improve performance and accelerate convergence, our method backpropagates the reward signal through the last steps of the sampling chain, enabling richer gradient feedback. We also propose a novel facial scoring mechanism that treats faces in ground-truth videos as facial feature pools, providing multi-angle facial information to enhance generalization. A KL-divergence regularization is further incorporated to stabilize training and prevent overfitting to the reward signal. Extensive experiments on Wan 2.2 I2V model and our in-house I2V model demonstrate the effectiveness of our method. Our project and code are available at \href{https://ipro-alimama.github.io/}{https://ipro-alimama.github.io/}.
Dual-Camera All-in-Focus Neural Radiance Fields
Apr 23, 2025We present the first framework capable of synthesizing the all-in-focus neural radiance field (NeRF) from inputs without manual refocusing. Without refocusing, the camera will automatically focus on the fixed object for all views, and current NeRF methods typically using one camera fail due to the consistent defocus blur and a lack of sharp reference. To restore the all-in-focus NeRF, we introduce the dual-camera from smartphones, where the ultra-wide camera has a wider depth-of-field (DoF) and the main camera possesses a higher resolution. The dual camera pair saves the high-fidelity details from the main camera and uses the ultra-wide camera's deep DoF as reference for all-in-focus restoration. To this end, we first implement spatial warping and color matching to align the dual camera, followed by a defocus-aware fusion module with learnable defocus parameters to predict a defocus map and fuse the aligned camera pair. We also build a multi-view dataset that includes image pairs of the main and ultra-wide cameras in a smartphone. Extensive experiments on this dataset verify that our solution, termed DC-NeRF, can produce high-quality all-in-focus novel views and compares favorably against strong baselines quantitatively and qualitatively. We further show DoF applications of DC-NeRF with adjustable blur intensity and focal plane, including refocusing and split diopter.
TacoDepth: Towards Efficient Radar-Camera Depth Estimation with One-stage Fusion
Apr 16, 2025



Radar-Camera depth estimation aims to predict dense and accurate metric depth by fusing input images and Radar data. Model efficiency is crucial for this task in pursuit of real-time processing on autonomous vehicles and robotic platforms. However, due to the sparsity of Radar returns, the prevailing methods adopt multi-stage frameworks with intermediate quasi-dense depth, which are time-consuming and not robust. To address these challenges, we propose TacoDepth, an efficient and accurate Radar-Camera depth estimation model with one-stage fusion. Specifically, the graph-based Radar structure extractor and the pyramid-based Radar fusion module are designed to capture and integrate the graph structures of Radar point clouds, delivering superior model efficiency and robustness without relying on the intermediate depth results. Moreover, TacoDepth can be flexible for different inference modes, providing a better balance of speed and accuracy. Extensive experiments are conducted to demonstrate the efficacy of our method. Compared with the previous state-of-the-art approach, TacoDepth improves depth accuracy and processing speed by 12.8% and 91.8%. Our work provides a new perspective on efficient Radar-Camera depth estimation.
Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
Mar 26, 2025
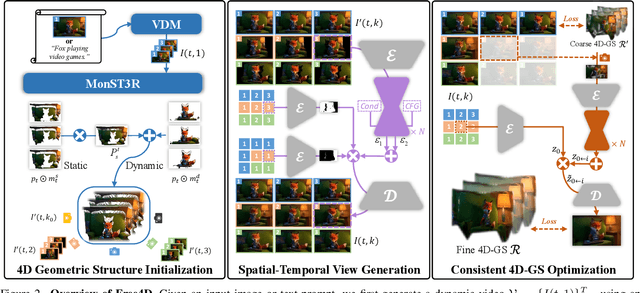
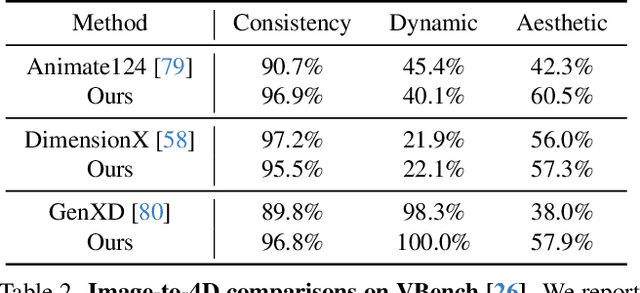

We present Free4D, a novel tuning-free framework for 4D scene generation from a single image. Existing methods either focus on object-level generation, making scene-level generation infeasible, or rely on large-scale multi-view video datasets for expensive training, with limited generalization ability due to the scarcity of 4D scene data. In contrast, our key insight is to distill pre-trained foundation models for consistent 4D scene representation, which offers promising advantages such as efficiency and generalizability. 1) To achieve this, we first animate the input image using image-to-video diffusion models followed by 4D geometric structure initialization. 2) To turn this coarse structure into spatial-temporal consistent multiview videos, we design an adaptive guidance mechanism with a point-guided denoising strategy for spatial consistency and a novel latent replacement strategy for temporal coherence. 3) To lift these generated observations into consistent 4D representation, we propose a modulation-based refinement to mitigate inconsistencies while fully leveraging the generated information. The resulting 4D representation enables real-time, controllable rendering, marking a significant advancement in single-image-based 4D scene generation.