 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Apr 09, 2026Personalized mobile agents that infer user preferences and calibrate proactive assistance hold great promise as everyday digital assistants, yet existing benchmarks fail to capture what this requires. Prior work evaluates preference recovery from static histories or intent prediction from fixed contexts. Neither tests whether an agent can elicit missing preferences through interaction, nor whether it can decide when to intervene, seek consent, or remain silent in a live GUI environment. We introduce KnowU-Bench, an online benchmark for personalized mobile agents built on a reproducible Android emulation environment, covering 42 general GUI tasks, 86 personalized tasks, and 64 proactive tasks. Unlike prior work that treats user preferences as static context, KnowU-Bench hides the user profile from the agent and exposes only behavioral logs, forcing genuine preference inference rather than context lookup. To support multi-turn preference elicitation, it instantiates an LLM-driven user simulator grounded in structured profiles, enabling realistic clarification dialogues and proactive consent handling. Beyond personalization, KnowU-Bench provides comprehensive evaluation of the complete proactive decision chain, including grounded GUI execution, consent negotiation, and post-rejection restraint, evaluated through a hybrid protocol combining rule-based verification with LLM-as-a-Judge scoring. Our experiments reveal a striking degradation: agents that excel at explicit task execution fall below 50% under vague instructions requiring user preference inference or intervention calibration, even for frontier models like Claude Sonnet 4.6. The core bottlenecks are not GUI navigation but preference acquisition and intervention calibration, exposing a fundamental gap between competent interface operation and trustworthy personal assistance.
AnchorSplat: Feed-Forward 3D Gaussian Splatting with 3D Geometric Priors
Apr 09, 2026Recent feed-forward Gaussian reconstruction models adopt a pixel-aligned formulation that maps each 2D pixel to a 3D Gaussian, entangling Gaussian representations tightly with the input images. In this paper, we propose AnchorSplat, a novel feed-forward 3DGS framework for scene-level reconstruction that represents the scene directly in 3D space. AnchorSplat introduces an anchor-aligned Gaussian representation guided by 3D geometric priors (e.g., sparse point clouds, voxels, or RGB-D point clouds), enabling a more geometry-aware renderable 3D Gaussians that is independent of image resolution and number of views. This design substantially reduces the number of required Gaussians, improving computational efficiency while enhancing reconstruction fidelity. Beyond the anchor-aligned design, we utilize a Gaussian Refiner to adjust the intermediate Gaussiansy via merely a few forward passes. Experiments on the ScanNet++ v2 NVS benchmark demonstrate the SOTA performance, outperforming previous methods with more view-consistent and substantially fewer Gaussian primitives.
StreamME: Simplify 3D Gaussian Avatar within Live Stream
Jul 22, 2025We propose StreamME, a method focuses on fast 3D avatar reconstruction. The StreamME synchronously records and reconstructs a head avatar from live video streams without any pre-cached data, enabling seamless integration of the reconstructed appearance into downstream applications. This exceptionally fast training strategy, which we refer to as on-the-fly training, is central to our approach. Our method is built upon 3D Gaussian Splatting (3DGS), eliminating the reliance on MLPs in deformable 3DGS and relying solely on geometry, which significantly improves the adaptation speed to facial expression. To further ensure high efficiency in on-the-fly training, we introduced a simplification strategy based on primary points, which distributes the point clouds more sparsely across the facial surface, optimizing points number while maintaining rendering quality. Leveraging the on-the-fly training capabilities, our method protects the facial privacy and reduces communication bandwidth in VR system or online conference. Additionally, it can be directly applied to downstream application such as animation, toonify, and relighting. Please refer to our project page for more details: https://songluchuan.github.io/StreamME/.
Video Motion Graphs
Mar 26, 2025We present Video Motion Graphs, a system designed to generate realistic human motion videos. Using a reference video and conditional signals such as music or motion tags, the system synthesizes new videos by first retrieving video clips with gestures matching the conditions and then generating interpolation frames to seamlessly connect clip boundaries. The core of our approach is HMInterp, a robust Video Frame Interpolation (VFI) model that enables seamless interpolation of discontinuous frames, even for complex motion scenarios like dancing. HMInterp i) employs a dual-branch interpolation approach, combining a Motion Diffusion Model for human skeleton motion interpolation with a diffusion-based video frame interpolation model for final frame generation. ii) adopts condition progressive training to effectively leverage identity strong and weak conditions, such as images and pose. These designs ensure both high video texture quality and accurate motion trajectory. Results show that our Video Motion Graphs outperforms existing generative- and retrieval-based methods for multi-modal conditioned human motion video generation. Project page can be found at https://h-liu1997.github.io/Video-Motion-Graphs/
Visual Persona: Foundation Model for Full-Body Human Customization
Mar 19, 2025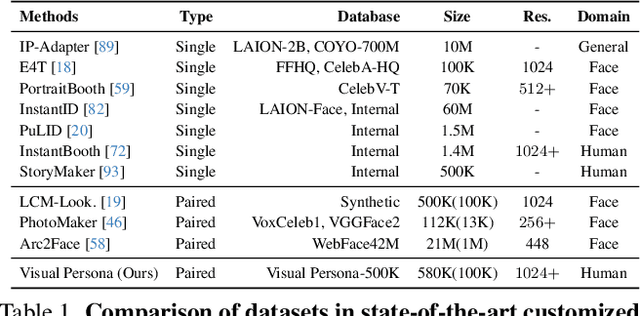



We introduce Visual Persona, a foundation model for text-to-image full-body human customization that, given a single in-the-wild human image, generates diverse images of the individual guided by text descriptions. Unlike prior methods that focus solely on preserving facial identity, our approach captures detailed full-body appearance, aligning with text descriptions for body structure and scene variations. Training this model requires large-scale paired human data, consisting of multiple images per individual with consistent full-body identities, which is notoriously difficult to obtain. To address this, we propose a data curation pipeline leveraging vision-language models to evaluate full-body appearance consistency, resulting in Visual Persona-500K, a dataset of 580k paired human images across 100k unique identities. For precise appearance transfer, we introduce a transformer encoder-decoder architecture adapted to a pre-trained text-to-image diffusion model, which augments the input image into distinct body regions, encodes these regions as local appearance features, and projects them into dense identity embeddings independently to condition the diffusion model for synthesizing customized images. Visual Persona consistently surpasses existing approaches, generating high-quality, customized images from in-the-wild inputs. Extensive ablation studies validate design choices, and we demonstrate the versatility of Visual Persona across various downstream tasks.
RigAnything: Template-Free Autoregressive Rigging for Diverse 3D Assets
Feb 13, 2025


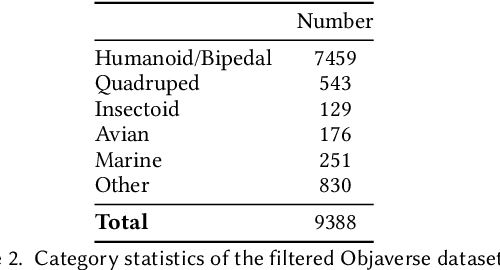
We present RigAnything, a novel autoregressive transformer-based model, which makes 3D assets rig-ready by probabilistically generating joints, skeleton topologies, and assigning skinning weights in a template-free manner. Unlike most existing auto-rigging methods, which rely on predefined skeleton template and are limited to specific categories like humanoid, RigAnything approaches the rigging problem in an autoregressive manner, iteratively predicting the next joint based on the global input shape and the previous prediction. While autoregressive models are typically used to generate sequential data, RigAnything extends their application to effectively learn and represent skeletons, which are inherently tree structures. To achieve this, we organize the joints in a breadth-first search (BFS) order, enabling the skeleton to be defined as a sequence of 3D locations and the parent index. Furthermore, our model improves the accuracy of position prediction by leveraging diffusion modeling, ensuring precise and consistent placement of joints within the hierarchy. This formulation allows the autoregressive model to efficiently capture both spatial and hierarchical relationships within the skeleton. Trained end-to-end on both RigNet and Objaverse datasets, RigAnything demonstrates state-of-the-art performance across diverse object types, including humanoids, quadrupeds, marine creatures, insects, and many more, surpassing prior methods in quality, robustness, generalizability, and efficiency. Please check our website for more details: https://www.liuisabella.com/RigAnything.
Free-viewpoint Human Animation with Pose-correlated Reference Selection
Dec 23, 2024



Diffusion-based human animation aims to animate a human character based on a source human image as well as driving signals such as a sequence of poses. Leveraging the generative capacity of diffusion model, existing approaches are able to generate high-fidelity poses, but struggle with significant viewpoint changes, especially in zoom-in/zoom-out scenarios where camera-character distance varies. This limits the applications such as cinematic shot type plan or camera control. We propose a pose-correlated reference selection diffusion network, supporting substantial viewpoint variations in human animation. Our key idea is to enable the network to utilize multiple reference images as input, since significant viewpoint changes often lead to missing appearance details on the human body. To eliminate the computational cost, we first introduce a novel pose correlation module to compute similarities between non-aligned target and source poses, and then propose an adaptive reference selection strategy, utilizing the attention map to identify key regions for animation generation. To train our model, we curated a large dataset from public TED talks featuring varied shots of the same character, helping the model learn synthesis for different perspectives. Our experimental results show that with the same number of reference images, our model performs favorably compared to the current SOTA methods under large viewpoint change. We further show that the adaptive reference selection is able to choose the most relevant reference regions to generate humans under free viewpoints.
Move-in-2D: 2D-Conditioned Human Motion Generation
Dec 17, 2024



Generating realistic human videos remains a challenging task, with the most effective methods currently relying on a human motion sequence as a control signal. Existing approaches often use existing motion extracted from other videos, which restricts applications to specific motion types and global scene matching. We propose Move-in-2D, a novel approach to generate human motion sequences conditioned on a scene image, allowing for diverse motion that adapts to different scenes. Our approach utilizes a diffusion model that accepts both a scene image and text prompt as inputs, producing a motion sequence tailored to the scene. To train this model, we collect a large-scale video dataset featuring single-human activities, annotating each video with the corresponding human motion as the target output. Experiments demonstrate that our method effectively predicts human motion that aligns with the scene image after projection. Furthermore, we show that the generated motion sequence improves human motion quality in video synthesis tasks.
Progressive Autoregressive Video Diffusion Models
Oct 10, 2024Current frontier video diffusion models have demonstrated remarkable results at generating high-quality videos. However, they can only generate short video clips, normally around 10 seconds or 240 frames, due to computation limitations during training. In this work, we show that existing models can be naturally extended to autoregressive video diffusion models without changing the architectures. Our key idea is to assign the latent frames with progressively increasing noise levels rather than a single noise level, which allows for fine-grained condition among the latents and large overlaps between the attention windows. Such progressive video denoising allows our models to autoregressively generate video frames without quality degradation or abrupt scene changes. We present state-of-the-art results on long video generation at 1 minute (1440 frames at 24 FPS). Videos from this paper are available at https://desaixie.github.io/pa-vdm/.
NECA: Neural Customizable Human Avatar
Mar 15, 2024


Human avatar has become a novel type of 3D asset with various applications. Ideally, a human avatar should be fully customizable to accommodate different settings and environments. In this work, we introduce NECA, an approach capable of learning versatile human representation from monocular or sparse-view videos, enabling granular customization across aspects such as pose, shadow, shape, lighting and texture. The core of our approach is to represent humans in complementary dual spaces and predict disentangled neural fields of geometry, albedo, shadow, as well as an external lighting, from which we are able to derive realistic rendering with high-frequency details via volumetric rendering. Extensive experiments demonstrate the advantage of our method over the state-of-the-art methods in photorealistic rendering, as well as various editing tasks such as novel pose synthesis and relighting. The code is available at https://github.com/iSEE-Laboratory/NECA.