 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
Mar 12, 2026Multi-modal large language models (MLLMs) have advanced general-purpose video understanding but struggle with long, high-resolution videos -- they process every pixel equally in their vision transformers (ViTs) or LLMs despite significant spatiotemporal redundancy. We introduce AutoGaze, a lightweight module that removes redundant patches before processed by a ViT or an MLLM. Trained with next-token prediction and reinforcement learning, AutoGaze autoregressively selects a minimal set of multi-scale patches that can reconstruct the video within a user-specified error threshold, eliminating redundancy while preserving information. Empirically, AutoGaze reduces visual tokens by 4x-100x and accelerates ViTs and MLLMs by up to 19x, enabling scaling MLLMs to 1K-frame 4K-resolution videos and achieving superior results on video benchmarks (e.g., 67.0% on VideoMME). Furthermore, we introduce HLVid: the first high-resolution, long-form video QA benchmark with 5-minute 4K-resolution videos, where an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. Project page: https://autogaze.github.io/.
LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Mar 03, 2026Feedforward geometric foundation models achieve strong short-window reconstruction, yet scaling them to minutes-long videos is bottlenecked by quadratic attention complexity or limited effective memory in recurrent designs. We present LoGeR (Long-context Geometric Reconstruction), a novel architecture that scales dense 3D reconstruction to extremely long sequences without post-optimization. LoGeR processes video streams in chunks, leveraging strong bidirectional priors for high-fidelity intra-chunk reasoning. To manage the critical challenge of coherence across chunk boundaries, we propose a learning-based hybrid memory module. This dual-component system combines a parametric Test-Time Training (TTT) memory to anchor the global coordinate frame and prevent scale drift, alongside a non-parametric Sliding Window Attention (SWA) mechanism to preserve uncompressed context for high-precision adjacent alignment. Remarkably, this memory architecture enables LoGeR to be trained on sequences of 128 frames, and generalize up to thousands of frames during inference. Evaluated across standard benchmarks and a newly repurposed VBR dataset with sequences of up to 19k frames, LoGeR substantially outperforms prior state-of-the-art feedforward methods--reducing ATE on KITTI by over 74%--and achieves robust, globally consistent reconstruction over unprecedented horizons.
EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data
Feb 18, 2026Human behavior is among the most scalable sources of data for learning physical intelligence, yet how to effectively leverage it for dexterous manipulation remains unclear. While prior work demonstrates human to robot transfer in constrained settings, it is unclear whether large scale human data can support fine grained, high degree of freedom dexterous manipulation. We present EgoScale, a human to dexterous manipulation transfer framework built on large scale egocentric human data. We train a Vision Language Action (VLA) model on over 20,854 hours of action labeled egocentric human video, more than 20 times larger than prior efforts, and uncover a log linear scaling law between human data scale and validation loss. This validation loss strongly correlates with downstream real robot performance, establishing large scale human data as a predictable supervision source. Beyond scale, we introduce a simple two stage transfer recipe: large scale human pretraining followed by lightweight aligned human robot mid training. This enables strong long horizon dexterous manipulation and one shot task adaptation with minimal robot supervision. Our final policy improves average success rate by 54% over a no pretraining baseline using a 22 DoF dexterous robotic hand, and transfers effectively to robots with lower DoF hands, indicating that large scale human motion provides a reusable, embodiment agnostic motor prior.
Learning a Generative Meta-Model of LLM Activations
Feb 06, 2026Existing approaches for analyzing neural network activations, such as PCA and sparse autoencoders, rely on strong structural assumptions. Generative models offer an alternative: they can uncover structure without such assumptions and act as priors that improve intervention fidelity. We explore this direction by training diffusion models on one billion residual stream activations, creating "meta-models" that learn the distribution of a network's internal states. We find that diffusion loss decreases smoothly with compute and reliably predicts downstream utility. In particular, applying the meta-model's learned prior to steering interventions improves fluency, with larger gains as loss decreases. Moreover, the meta-model's neurons increasingly isolate concepts into individual units, with sparse probing scores that scale as loss decreases. These results suggest generative meta-models offer a scalable path toward interpretability without restrictive structural assumptions. Project page: https://generative-latent-prior.github.io.
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Jan 16, 2026Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.
It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
Dec 31, 2025Contemporary text-to-image models exhibit a surprising degree of mode collapse, as can be seen when sampling several images given the same text prompt. While previous work has attempted to address this issue by steering the model using guidance mechanisms, or by generating a large pool of candidates and refining them, in this work we take a different direction and aim for diversity in generations via noise optimization. Specifically, we show that a simple noise optimization objective can mitigate mode collapse while preserving the fidelity of the base model. We also analyze the frequency characteristics of the noise and show that alternative noise initializations with different frequency profiles can improve both optimization and search. Our experiments demonstrate that noise optimization yields superior results in terms of generation quality and variety.
Latent Implicit Visual Reasoning
Dec 24, 2025While Large Multimodal Models (LMMs) have made significant progress, they remain largely text-centric, relying on language as their core reasoning modality. As a result, they are limited in their ability to handle reasoning tasks that are predominantly visual. Recent approaches have sought to address this by supervising intermediate visual steps with helper images, depth maps, or image crops. However, these strategies impose restrictive priors on what "useful" visual abstractions look like, add heavy annotation costs, and struggle to generalize across tasks. To address this critical limitation, we propose a task-agnostic mechanism that trains LMMs to discover and use visual reasoning tokens without explicit supervision. These tokens attend globally and re-encode the image in a task-adaptive way, enabling the model to extract relevant visual information without hand-crafted supervision. Our approach outperforms direct fine-tuning and achieves state-of-the-art results on a diverse range of vision-centric tasks -- including those where intermediate abstractions are hard to specify -- while also generalizing to multi-task instruction tuning.
Visually Prompted Benchmarks Are Surprisingly Fragile
Dec 19, 2025



A key challenge in evaluating VLMs is testing models' ability to analyze visual content independently from their textual priors. Recent benchmarks such as BLINK probe visual perception through visual prompting, where questions about visual content are paired with coordinates to which the question refers, with the coordinates explicitly marked in the image itself. While these benchmarks are an important part of VLM evaluation, we find that existing models are surprisingly fragile to seemingly irrelevant details of visual prompting: simply changing a visual marker from red to blue can completely change rankings among models on a leaderboard. By evaluating nine commonly-used open- and closed-source VLMs on two visually prompted tasks, we demonstrate how details in benchmark setup, including visual marker design and dataset size, have a significant influence on model performance and leaderboard rankings. These effects can even be exploited to lift weaker models above stronger ones; for instance, slightly increasing the size of the visual marker results in open-source InternVL3-8B ranking alongside or better than much larger proprietary models like Gemini 2.5 Pro. We further show that low-level inference choices that are often ignored in benchmarking, such as JPEG compression levels in API calls, can also cause model lineup changes. These details have substantially larger impacts on visually prompted benchmarks than on conventional semantic VLM evaluations. To mitigate this instability, we curate existing datasets to create VPBench, a larger visually prompted benchmark with 16 visual marker variants. VPBench and additional analysis tools are released at https://lisadunlap.github.io/vpbench/.
DAVE: A VLM Vision Encoder for Document Understanding and Web Agents
Dec 19, 2025While Vision-language models (VLMs) have demonstrated remarkable performance across multi-modal tasks, their choice of vision encoders presents a fundamental weakness: their low-level features lack the robust structural and spatial information essential for document understanding and web agents. To bridge this gap, we introduce DAVE, a vision encoder purpose-built for VLMs and tailored for these tasks. Our training pipeline is designed to leverage abundant unlabeled data to bypass the need for costly large-scale annotations for document and web images. We begin with a self-supervised pretraining stage on unlabeled images, followed by a supervised autoregressive pretraining stage, where the model learns tasks like parsing and localization from limited, high-quality data. Within the supervised stage, we adopt two strategies to improve our encoder's alignment with both general visual knowledge and diverse document and web agentic tasks: (i) We introduce a novel model-merging scheme, combining encoders trained with different text decoders to ensure broad compatibility with different web agentic architectures. (ii) We use ensemble training to fuse features from pretrained generalist encoders (e.g., SigLIP2) with our own document and web-specific representations. Extensive experiments on classic document tasks, VQAs, web localization, and agent-based benchmarks validate the effectiveness of our approach, establishing DAVE as a strong vision encoder for document and web applications.
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025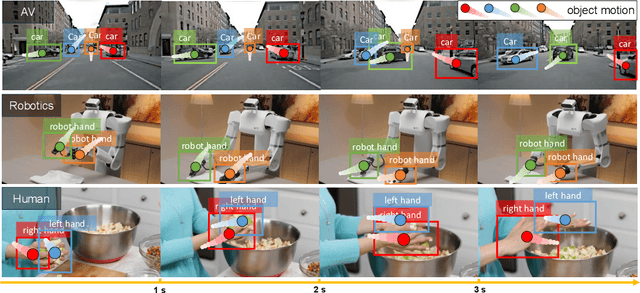
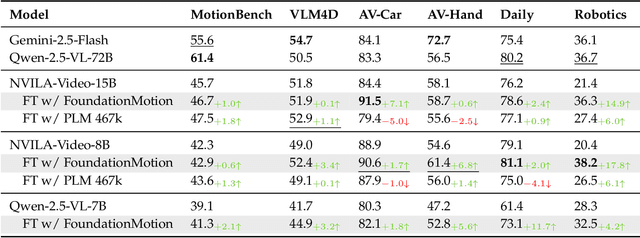
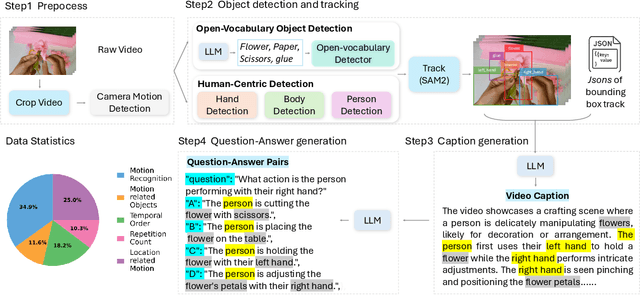

Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.