 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
STRNet: Visual Navigation with Spatio-Temporal Representation through Dynamic Graph Aggregation
Apr 03, 2026Visual navigation requires the robot to reach a specified goal such as an image, based on a sequence of first-person visual observations. While recent learning-based approaches have made significant progress, they often focus on improving policy heads or decision strategies while relying on simplistic feature encoders and temporal pooling to represent visual input. This leads to the loss of fine-grained spatial and temporal structure, ultimately limiting accurate action prediction and progress estimation. In this paper, we propose a unified spatio-temporal representation framework that enhances visual encoding for robotic navigation. Our approach extracts features from both image sequences and goal observations, and fuses them using the designed spatio-temporal fusion module. This module performs spatial graph reasoning within each frame and models temporal dynamics using a hybrid temporal shift module combined with multi-resolution difference-aware convolution. Experimental results demonstrate that our approach consistently improves navigation performance and offers a generalizable visual backbone for goal-conditioned control. Code is available at \href{https://github.com/hren20/STRNet}{https://github.com/hren20/STRNet}.
SaSaSaSa2VA: 2nd Place of the 5th PVUW MeViS-Text Track
Mar 28, 2026Referring video object segmentation (RVOS) commonly grounds targets in videos based on static textual cues. MeViS benchmark extends this by incorporating motion-centric expressions (referring & reasoning motion expressions) and introducing no-target queries. Extending SaSaSa2VA, where increased input frames and [SEG] tokens already strengthen the Sa2VA backbone, we adopt a simple yet effective target existence-aware verification mechanism, leading to Still Awesome SaSaSa2VA (SaSaSaSa2VA). Despite its simplicity, the method achieves a final score of 89.19 in the 5th PVUW Challenge (MeViS-Text Track), securing 2nd place. Both quantitative results and ablations suggest that this existence-aware verification strategy is sufficient to unlock strong performance on motion-centric referring tasks.
InstaVSR: Taming Diffusion for Efficient and Temporally Consistent Video Super-Resolution
Mar 27, 2026Video super-resolution (VSR) seeks to reconstruct high-resolution frames from low-resolution inputs. While diffusion-based methods have substantially improved perceptual quality, extending them to video remains challenging for two reasons: strong generative priors can introduce temporal instability, and multi-frame diffusion pipelines are often too expensive for practical deployment. To address both challenges simultaneously, we propose InstaVSR, a lightweight diffusion framework for efficient video super-resolution. InstaVSR combines three ingredients: (1) a pruned one-step diffusion backbone that removes several costly components from conventional diffusion-based VSR pipelines, (2) recurrent training with flow-guided temporal regularization to improve frame-to-frame stability, and (3) dual-space adversarial learning in latent and pixel spaces to preserve perceptual quality after backbone simplification. On an NVIDIA RTX 4090, InstaVSR processes a 30-frame video at 2K$\times$2K resolution in under one minute with only 7 GB of memory usage, substantially reducing the computational cost compared to existing diffusion-based methods while maintaining favorable perceptual quality with significantly smoother temporal transitions.
Recover to Predict: Progressive Retrospective Learning for Variable-Length Trajectory Prediction
Mar 11, 2026Trajectory prediction is critical for autonomous driving, enabling safe and efficient planning in dense, dynamic traffic. Most existing methods optimize prediction accuracy under fixed-length observations. However, real-world driving often yields variable-length, incomplete observations, posing a challenge to these methods. A common strategy is to directly map features from incomplete observations to those from complete ones. This one-shot mapping, however, struggles to learn accurate representations for short trajectories due to significant information gaps. To address this issue, we propose a Progressive Retrospective Framework (PRF), which gradually aligns features from incomplete observations with those from complete ones via a cascade of retrospective units. Each unit consists of a Retrospective Distillation Module (RDM) and a Retrospective Prediction Module (RPM), where RDM distills features and RPM recovers previous timesteps using the distilled features. Moreover, we propose a Rolling-Start Training Strategy (RSTS) that enhances data efficiency during PRF training. PRF is plug-and-play with existing methods. Extensive experiments on datasets Argoverse 2 and Argoverse 1 demonstrate the effectiveness of PRF. Code is available at https://github.com/zhouhao94/PRF.
SAMTok: Representing Any Mask with Two Words
Jan 22, 2026Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.
Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Dec 18, 2025
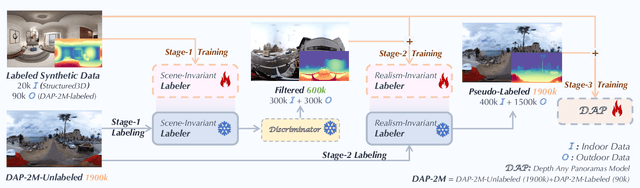

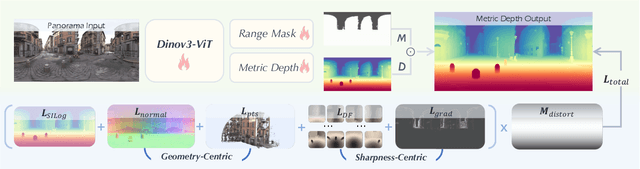
In this work, we present a panoramic metric depth foundation model that generalizes across diverse scene distances. We explore a data-in-the-loop paradigm from the view of both data construction and framework design. We collect a large-scale dataset by combining public datasets, high-quality synthetic data from our UE5 simulator and text-to-image models, and real panoramic images from the web. To reduce domain gaps between indoor/outdoor and synthetic/real data, we introduce a three-stage pseudo-label curation pipeline to generate reliable ground truth for unlabeled images. For the model, we adopt DINOv3-Large as the backbone for its strong pre-trained generalization, and introduce a plug-and-play range mask head, sharpness-centric optimization, and geometry-centric optimization to improve robustness to varying distances and enforce geometric consistency across views. Experiments on multiple benchmarks (e.g., Stanford2D3D, Matterport3D, and Deep360) demonstrate strong performance and zero-shot generalization, with particularly robust and stable metric predictions in diverse real-world scenes. The project page can be found at: \href{https://insta360-research-team.github.io/DAP_website/} {https://insta360-research-team.github.io/DAP\_website/}
Seg-VAR: Image Segmentation with Visual Autoregressive Modeling
Nov 16, 2025While visual autoregressive modeling (VAR) strategies have shed light on image generation with the autoregressive models, their potential for segmentation, a task that requires precise low-level spatial perception, remains unexplored. Inspired by the multi-scale modeling of classic Mask2Former-based models, we propose Seg-VAR, a novel framework that rethinks segmentation as a conditional autoregressive mask generation problem. This is achieved by replacing the discriminative learning with the latent learning process. Specifically, our method incorporates three core components: (1) an image encoder generating latent priors from input images, (2) a spatial-aware seglat (a latent expression of segmentation mask) encoder that maps segmentation masks into discrete latent tokens using a location-sensitive color mapping to distinguish instances, and (3) a decoder reconstructing masks from these latents. A multi-stage training strategy is introduced: first learning seglat representations via image-seglat joint training, then refining latent transformations, and finally aligning image-encoder-derived latents with seglat distributions. Experiments show Seg-VAR outperforms previous discriminative and generative methods on various segmentation tasks and validation benchmarks. By framing segmentation as a sequential hierarchical prediction task, Seg-VAR opens new avenues for integrating autoregressive reasoning into spatial-aware vision systems. Code will be available at https://github.com/rkzheng99/Seg-VAR.
PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
Sep 16, 2025Omnidirectional vision, using 360-degree vision to understand the environment, has become increasingly critical across domains like robotics, industrial inspection, and environmental monitoring. Compared to traditional pinhole vision, omnidirectional vision provides holistic environmental awareness, significantly enhancing the completeness of scene perception and the reliability of decision-making. However, foundational research in this area has historically lagged behind traditional pinhole vision. This talk presents an emerging trend in the embodied AI era: the rapid development of omnidirectional vision, driven by growing industrial demand and academic interest. We highlight recent breakthroughs in omnidirectional generation, omnidirectional perception, omnidirectional understanding, and related datasets. Drawing on insights from both academia and industry, we propose an ideal panoramic system architecture in the embodied AI era, PANORAMA, which consists of four key subsystems. Moreover, we offer in-depth opinions related to emerging trends and cross-community impacts at the intersection of panoramic vision and embodied AI, along with the future roadmap and open challenges. This overview synthesizes state-of-the-art advancements and outlines challenges and opportunities for future research in building robust, general-purpose omnidirectional AI systems in the embodied AI era.
One Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025



Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama