 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombee: Scaling Prompt Learning for Self-Improving Language Model Agents
Apr 05, 2026Recent advances in prompt learning allow large language model agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing
Mar 09, 2026Diffusion Transformers (DiTs) have become a leading backbone for video generation, yet their quadratic attention cost remains a major bottleneck. Sparse attention reduces this cost by computing only a subset of attention blocks. However, prior methods often either drop the remaining blocks, which incurs information loss, or rely on learned predictors to approximate them, introducing training overhead and potential output distribution shifting. In this paper, we show that the missing contributions can be recovered without training: after semantic clustering, keys and values within each block exhibit strong similarity and can be well summarized by a small set of cluster centroids. Based on this observation, we introduce SVG-EAR, a parameter-free linear compensation branch that uses the centroid to approximate skipped blocks and recover their contributions. While centroid compensation is accurate for most blocks, it can fail on a small subset. Standard sparsification typically selects blocks by attention scores, which indicate where the model places its attention mass, but not where the approximation error would be largest. SVG-EAR therefore performs error-aware routing: a lightweight probe estimates the compensation error for each block, and we compute exactly the blocks with the highest error-to-cost ratio while compensating for skipped blocks. We provide theoretical guarantees that relate attention reconstruction error to clustering quality, and empirically show that SVG-EAR improves the quality-efficiency trade-off and increases throughput at the same generation fidelity on video diffusion tasks. Overall, SVG-EAR establishes a clear Pareto frontier over prior approaches, achieving up to 1.77$\times$ and 1.93$\times$ speedups while maintaining PSNRs of up to 29.759 and 31.043 on Wan2.2 and HunyuanVideo, respectively.
SageBwd: A Trainable Low-bit Attention
Mar 02, 2026Low-bit attention, such as SageAttention, has emerged as an effective approach for accelerating model inference, but its applicability to training remains poorly understood. In prior work, we introduced SageBwd, a trainable INT8 attention that quantizes six of seven attention matrix multiplications while preserving fine-tuning performance. However, SageBwd exhibited a persistent performance gap to full-precision attention (FPA) during pre-training. In this work, we investigate why this gap occurs and demonstrate that SageBwd matches full-precision attention during pretraining. Through experiments and theoretical analysis, we reach a few important insights and conclusions: (i) QK-norm is necessary for stable training at large tokens per step, (ii) quantization errors primarily arise from the backward-pass score gradient dS, (iii) reducing tokens per step enables SageBwd to match FPA performance in pre-training, and (iv) K-smoothing remains essential for training stability, while Q-smoothing provides limited benefit during pre-training.
K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model
Feb 26, 2026Optimizing GPU kernels is critical for efficient modern machine learning systems yet remains challenging due to the complex interplay of design factors and rapid hardware evolution. Existing automated approaches typically treat Large Language Models (LLMs) merely as stochastic code generators within heuristic-guided evolutionary loops. These methods often struggle with complex kernels requiring coordinated, multi-step structural transformations, as they lack explicit planning capabilities and frequently discard promising strategies due to inefficient or incorrect intermediate implementations. To address this, we propose Search via Co-Evolving World Model and build K-Search based on this method. By replacing static search heuristics with a co-evolving world model, our framework leverages LLMs' prior domain knowledge to guide the search, actively exploring the optimization space. This approach explicitly decouples high-level algorithmic planning from low-level program instantiation, enabling the system to navigate non-monotonic optimization paths while remaining resilient to temporary implementation defects. We evaluate K-Search on diverse, complex kernels from FlashInfer, including GQA, MLA, and MoE kernels. Our results show that K-Search significantly outperforms state-of-the-art evolutionary search methods, achieving an average 2.10x improvement and up to a 14.3x gain on complex MoE kernels. On the GPUMode TriMul task, K-Search achieves state-of-the-art performance on H100, reaching 1030us and surpassing both prior evolution and human-designed solutions.
SLA2: Sparse-Linear Attention with Learnable Routing and QAT
Feb 13, 2026Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Dec 18, 2025We introduce TurboDiffusion, a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200x while maintaining video quality. TurboDiffusion mainly relies on several components for acceleration: (1) Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation. (2) Step distillation: TurboDiffusion adopts rCM for efficient step distillation. (3) W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model. In addition, TurboDiffusion incorporates several other engineering optimizations. We conduct experiments on the Wan2.2-I2V-14B-720P, Wan2.1-T2V-1.3B-480P, Wan2.1-T2V-14B-720P, and Wan2.1-T2V-14B-480P models. Experimental results show that TurboDiffusion achieves 100-200x speedup for video generation even on a single RTX 5090 GPU, while maintaining comparable video quality. The GitHub repository, which includes model checkpoints and easy-to-use code, is available at https://github.com/thu-ml/TurboDiffusion.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Discovering Divergent Representations between Text-to-Image Models
Sep 10, 2025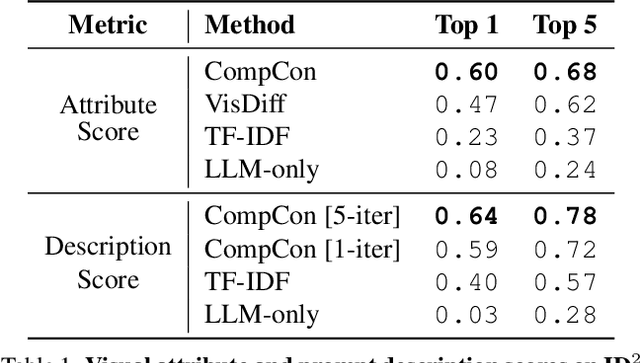
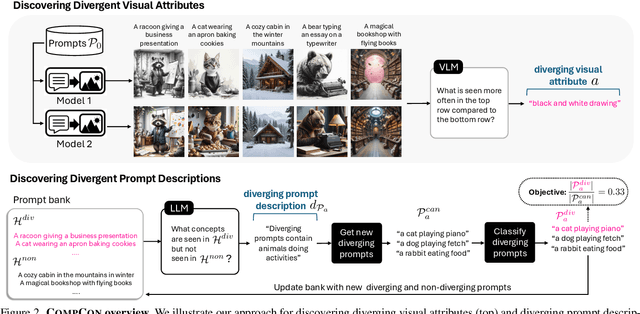


In this paper, we investigate when and how visual representations learned by two different generative models diverge. Given two text-to-image models, our goal is to discover visual attributes that appear in images generated by one model but not the other, along with the types of prompts that trigger these attribute differences. For example, "flames" might appear in one model's outputs when given prompts expressing strong emotions, while the other model does not produce this attribute given the same prompts. We introduce CompCon (Comparing Concepts), an evolutionary search algorithm that discovers visual attributes more prevalent in one model's output than the other, and uncovers the prompt concepts linked to these visual differences. To evaluate CompCon's ability to find diverging representations, we create an automated data generation pipeline to produce ID2, a dataset of 60 input-dependent differences, and compare our approach to several LLM- and VLM-powered baselines. Finally, we use CompCon to compare popular text-to-image models, finding divergent representations such as how PixArt depicts prompts mentioning loneliness with wet streets and Stable Diffusion 3.5 depicts African American people in media professions. Code at: https://github.com/adobe-research/CompCon
LEANN: A Low-Storage Vector Index
Jun 09, 2025Embedding-based search is widely used in applications such as recommendation and retrieval-augmented generation (RAG). Recently, there is a growing demand to support these capabilities over personal data stored locally on devices. However, maintaining the necessary data structure associated with the embedding-based search is often infeasible due to its high storage overhead. For example, indexing 100 GB of raw data requires 150 to 700 GB of storage, making local deployment impractical. Reducing this overhead while maintaining search quality and latency becomes a critical challenge. In this paper, we present LEANN, a storage-efficient approximate nearest neighbor (ANN) search index optimized for resource-constrained personal devices. LEANN combines a compact graph-based structure with an efficient on-the-fly recomputation strategy to enable fast and accurate retrieval with minimal storage overhead. Our evaluation shows that LEANN reduces index size to under 5% of the original raw data, achieving up to 50 times smaller storage than standard indexes, while maintaining 90% top-3 recall in under 2 seconds on real-world question answering benchmarks.