 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndian Number Plates Dataset
Papers and Code
Exploration of an End-to-End Automatic Number-plate Recognition neural network for Indian datasets
Jul 14, 2022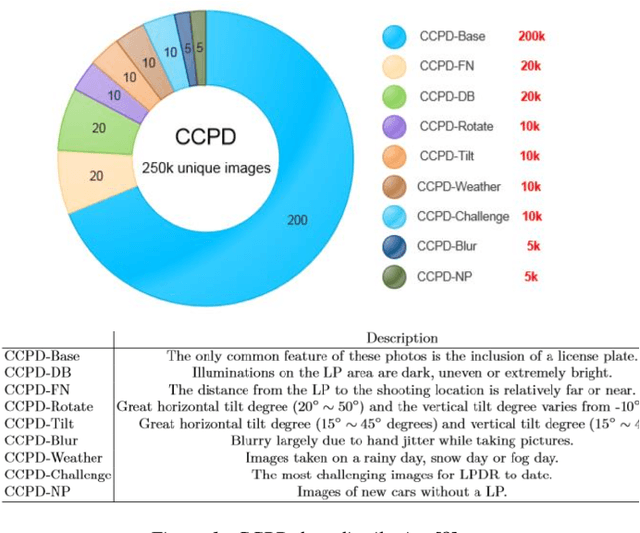



Indian vehicle number plates have wide variety in terms of size, font, script and shape. Development of Automatic Number Plate Recognition (ANPR) solutions is therefore challenging, necessitating a diverse dataset to serve as a collection of examples. However, a comprehensive dataset of Indian scenario is missing, thereby, hampering the progress towards publicly available and reproducible ANPR solutions. Many countries have invested efforts to develop comprehensive ANPR datasets like Chinese City Parking Dataset (CCPD) for China and Application-oriented License Plate (AOLP) dataset for US. In this work, we release an expanding dataset presently consisting of 1.5k images and a scalable and reproducible procedure of enhancing this dataset towards development of ANPR solution for Indian conditions. We have leveraged this dataset to explore an End-to-End (E2E) ANPR architecture for Indian scenario which was originally proposed for Chinese Vehicle number-plate recognition based on the CCPD dataset. As we customized the architecture for our dataset, we came across insights, which we have discussed in this paper. We report the hindrances in direct reusability of the model provided by the authors of CCPD because of the extreme diversity in Indian number plates and differences in distribution with respect to the CCPD dataset. An improvement of 42.86% was observed in LP detection after aligning the characteristics of Indian dataset with Chinese dataset. In this work, we have also compared the performance of the E2E number-plate detection model with YOLOv5 model, pre-trained on COCO dataset and fine-tuned on Indian vehicle images. Given that the number Indian vehicle images used for fine-tuning the detection module and yolov5 were same, we concluded that it is more sample efficient to develop an ANPR solution for Indian conditions based on COCO dataset rather than CCPD dataset.
Indian Licence Plate Dataset in the wild
Nov 11, 2021

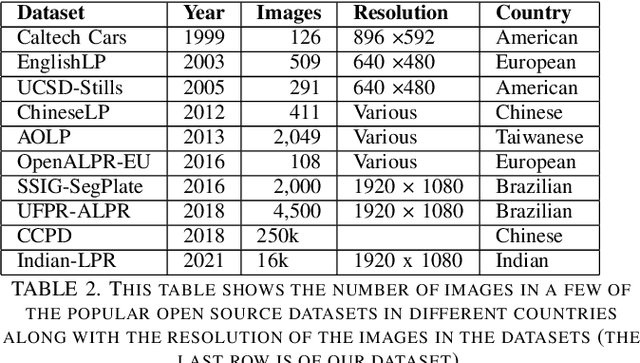

Indian Licence Plate Detection is a problem that has not been explored much at an open-source level.There are proprietary solutions available for it, but there is no big open-source dataset that can be used to perform experiments and test different approaches.Most of the large datasets available are for countries like China, Brazil, but the model trained on these datasets does not perform well on Indian plates because the font styles and plate designs used vary significantly from country to country.This paper introduces an Indian license plate dataset with 16192 images and 21683 plate plates annotated with 4 points for each plate and each character in the corresponding plate.We present a benchmark model that uses semantic segmentation to solve number plate detection. We propose a two-stage approach in which the first stage is for localizing the plate, and the second stage is to read the text in cropped plate image.We tested benchmark object detection and semantic segmentation model, for the second stage, we used lprnet based OCR.