 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndian Licence Plate Dataset in the wild
Nov 11, 2021

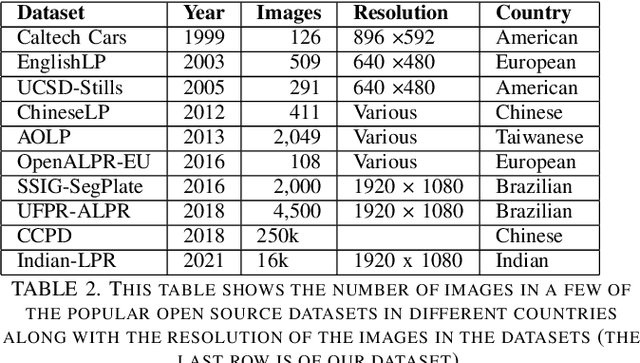

Indian Licence Plate Detection is a problem that has not been explored much at an open-source level.There are proprietary solutions available for it, but there is no big open-source dataset that can be used to perform experiments and test different approaches.Most of the large datasets available are for countries like China, Brazil, but the model trained on these datasets does not perform well on Indian plates because the font styles and plate designs used vary significantly from country to country.This paper introduces an Indian license plate dataset with 16192 images and 21683 plate plates annotated with 4 points for each plate and each character in the corresponding plate.We present a benchmark model that uses semantic segmentation to solve number plate detection. We propose a two-stage approach in which the first stage is for localizing the plate, and the second stage is to read the text in cropped plate image.We tested benchmark object detection and semantic segmentation model, for the second stage, we used lprnet based OCR.