 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Action Recognition with Transformer-based Video Semantic Embedding
Paper and Code
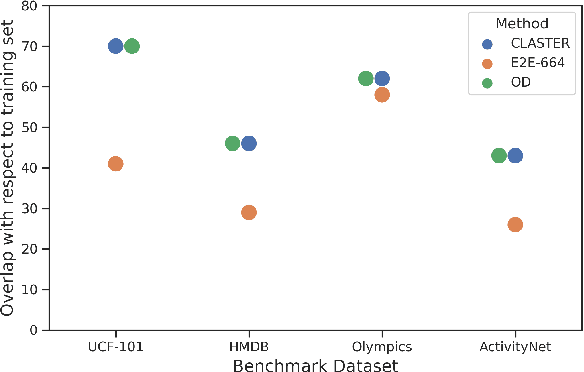

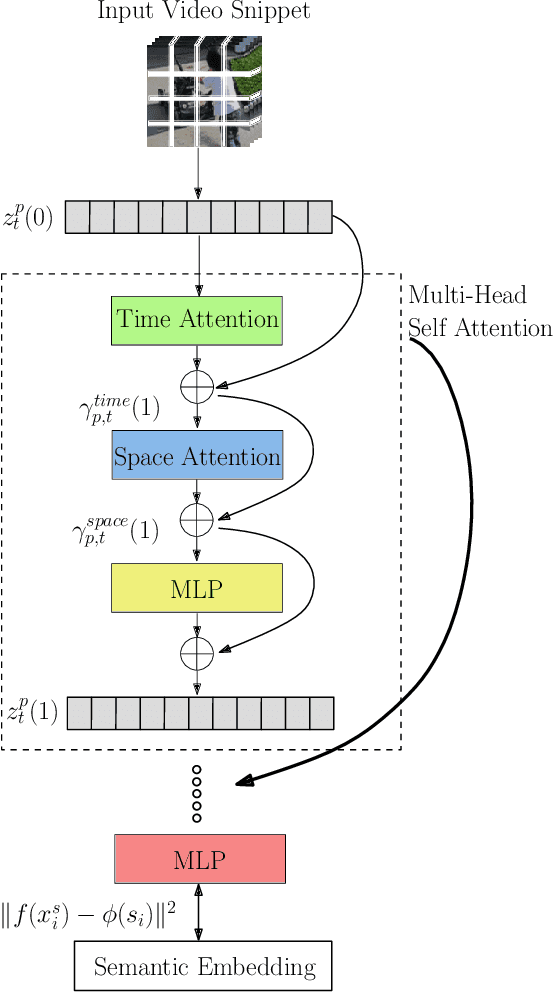
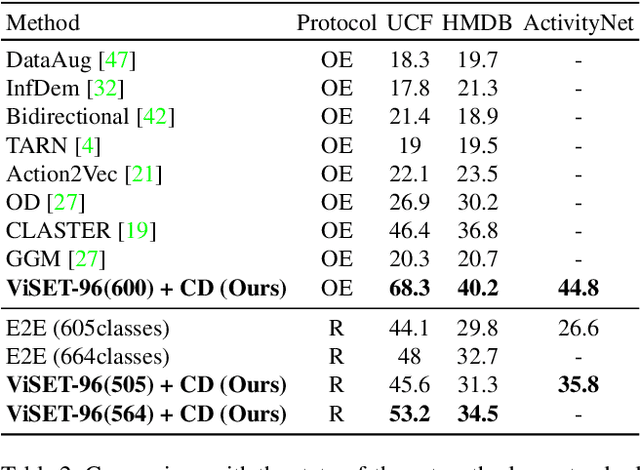
While video action recognition has been an active area of research for several years, zero-shot action recognition has only recently started gaining traction. However, there is a lack of a formal definition for the zero-shot learning paradigm leading to uncertainty about classes that can be considered as previously unseen. In this work, we take a new comprehensive look at the inductive zero-shot action recognition problem from a realistic standpoint. Specifically, we advocate for a concrete formulation for zero-shot action recognition that avoids an exact overlap between the training and testing classes and also limits the intra-class variance; and propose a novel end-to-end trained transformer model which is capable of capturing long range spatiotemporal dependencies efficiently, contrary to existing approaches which use 3D-CNNs. The proposed approach outperforms the existing state-of-the-art algorithms in many settings on all benchmark datasets by a wide margin.