 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Paper and Code
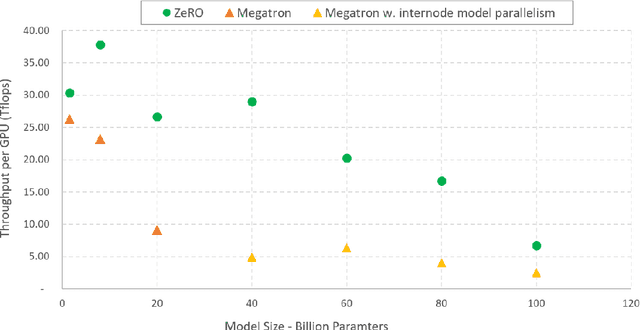
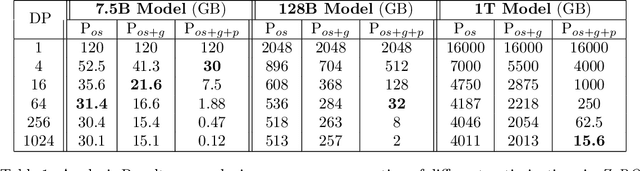
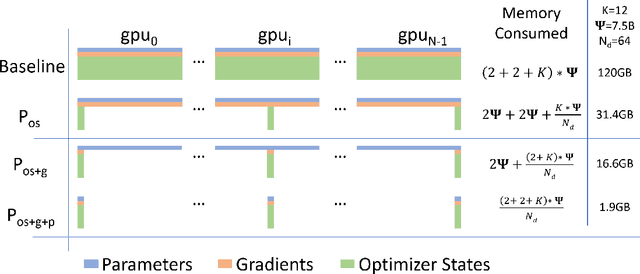
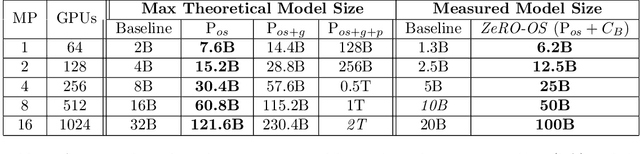
Training large DL models with billions and potentially trillions of parameters is challenging. Existing solutions exhibit fundamental limitations to obtain both memory and scaling (computation/communication) efficiency together. Data parallelism does not help reduce memory footprint per device: a model with 1.5 billion parameters or more runs out of memory. Model parallelism hardly scales efficiently beyond multiple devices of a single node due to fine-grained computation and expensive communication. We develop a novel solution, Zero Redundancy Optimizer (ZeRO), to optimize memory, achieving both memory efficiency and scaling efficiency. Unlike basic data parallelism where memory states are replicated across data-parallel processes, ZeRO partitions model states instead, to scale the model size linearly with the number of devices. Furthermore, it retains scaling efficiency via computation and communication rescheduling and by reducing the model parallelism degree required to run large models. Our analysis on memory requirements and communication volume demonstrates: ZeRO has the potential to scale beyond 1 Trillion parameters using today's hardware (e.g., 1024 GPUs, 64 DGX-2 nodes). To meet near-term scaling goals and serve as a demonstration of ZeRO's capability, we implemented stage-1 optimizations of ZeRO (out of 3 stages in total described in the paper) and tested this ZeRO-OS version. ZeRO-OS reduces memory and boosts model size by 4x compared with the state-of-art, scaling up to 100B parameters. Moving forward, we will work on unlocking stage-2 optimizations, with up to 8x memory savings per device, and ultimately stage-3 optimizations, reducing memory linearly with respect to the number of devices and potentially scaling to models of arbitrary size. We are excited to transform very large models from impossible to train to feasible and efficient to train!