 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYin Yang Convolutional Nets: Image Manifold Extraction by the Analysis of Opposites
Paper and Code
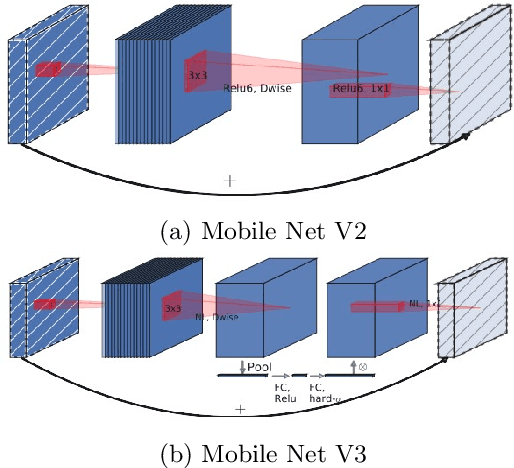
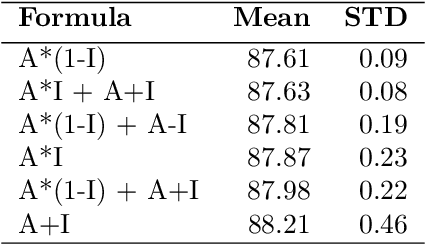
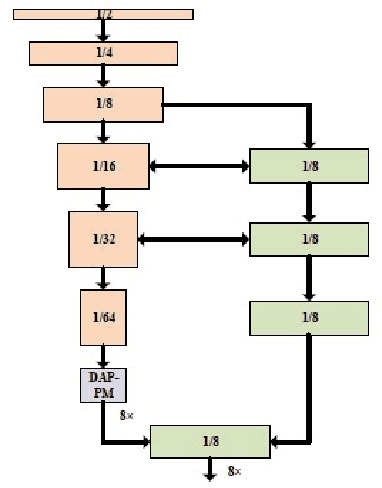

Computer vision in general presented several advances such as training optimizations, new architectures (pure attention, efficient block, vision language models, generative models, among others). This have improved performance in several tasks such as classification, and others. However, the majority of these models focus on modifications that are taking distance from realistic neuroscientific approaches related to the brain. In this work, we adopt a more bio-inspired approach and present the Yin Yang Convolutional Network, an architecture that extracts visual manifold, its blocks are intended to separate analysis of colors and forms at its initial layers, simulating occipital lobe's operations. Our results shows that our architecture provides State-of-the-Art efficiency among low parameter architectures in the dataset CIFAR-10. Our first model reached 93.32\% test accuracy, 0.8\% more than the older SOTA in this category, while having 150k less parameters (726k in total). Our second model uses 52k parameters, losing only 3.86\% test accuracy. We also performed an analysis on ImageNet, where we reached 66.49\% validation accuracy with 1.6M parameters. We make the code publicly available at: https://github.com/NoSavedDATA/YinYang_CNN.