Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXGBoost: Scalable GPU Accelerated Learning
Paper and Code
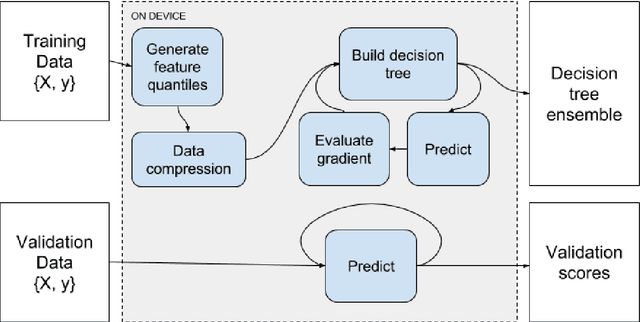
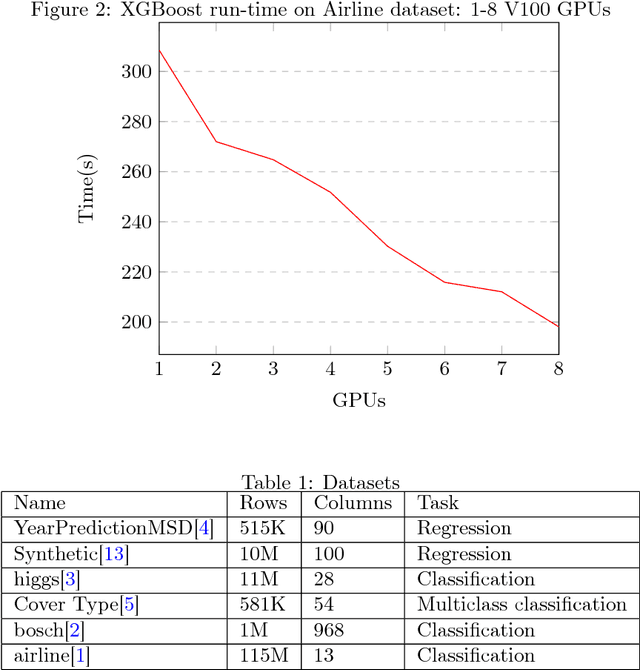
We describe the multi-GPU gradient boosting algorithm implemented in the XGBoost library (https://github.com/dmlc/xgboost). Our algorithm allows fast, scalable training on multi-GPU systems with all of the features of the XGBoost library. We employ data compression techniques to minimise the usage of scarce GPU memory while still allowing highly efficient implementation. Using our algorithm we show that it is possible to process 115 million training instances in under three minutes on a publicly available cloud computing instance. The algorithm is implemented using end-to-end GPU parallelism, with prediction, gradient calculation, feature quantisation, decision tree construction and evaluation phases all computed on device.
View paper on