 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXGBD: Explanation-Guided Graph Backdoor Detection
Paper and Code

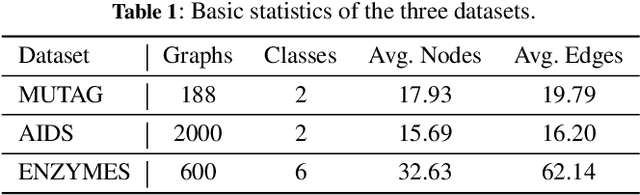


Backdoor attacks pose a significant security risk to graph learning models. Backdoors can be embedded into the target model by inserting backdoor triggers into the training dataset, causing the model to make incorrect predictions when the trigger is present. To counter backdoor attacks, backdoor detection has been proposed. An emerging detection strategy in the vision and NLP domains is based on an intriguing phenomenon: when training models on a mixture of backdoor and clean samples, the loss on backdoor samples drops significantly faster than on clean samples, allowing backdoor samples to be easily detected by selecting samples with the lowest loss values. However, the ignorance of topological feature information on graph data limits its detection effectiveness when applied directly to the graph domain. To this end, we propose an explanation-guided backdoor detection method to take advantage of the topological information. Specifically, we train a helper model on the graph dataset, feed graph samples into the model, and then adopt explanation methods to attribute model prediction to an important subgraph. We observe that backdoor samples have distinct attribution distribution than clean samples, so the explanatory subgraph could serve as more discriminative features for detecting backdoor samples. Comprehensive experiments on multiple popular datasets and attack methods demonstrate the effectiveness and explainability of our method. Our code is available: https://github.com/GuanZihan/GNN_backdoor_detection.