 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-DC: Explainable Deep Clustering based on Learnable Spectrogram Templates
Paper and Code
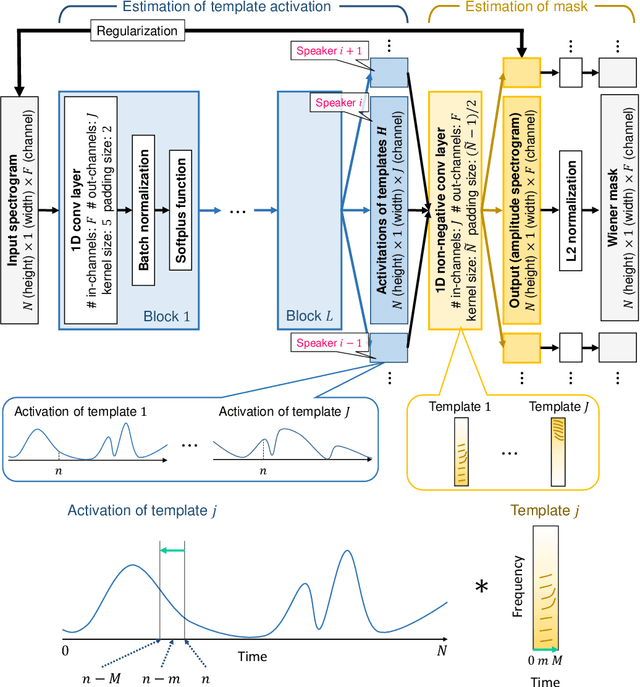
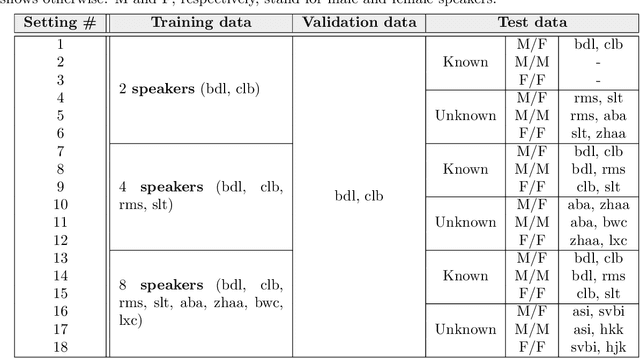
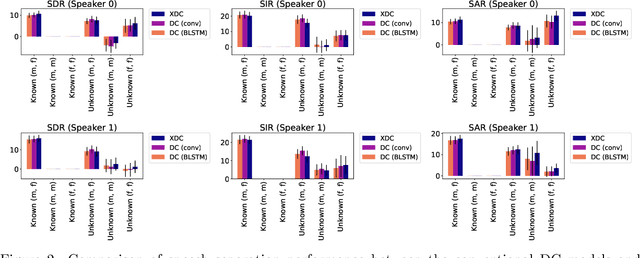
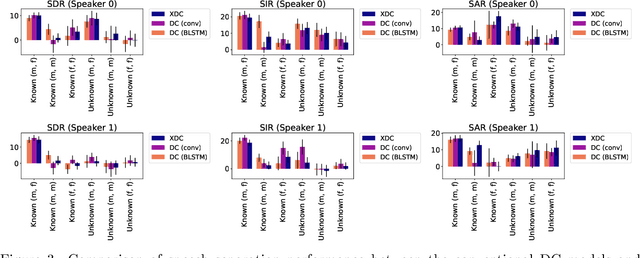
Deep neural networks (DNNs) have achieved substantial predictive performance in various speech processing tasks. Particularly, it has been shown that a monaural speech separation task can be successfully solved with a DNN-based method called deep clustering (DC), which uses a DNN to describe the process of assigning a continuous vector to each time-frequency (TF) bin and measure how likely each pair of TF bins is to be dominated by the same speaker. In DC, the DNN is trained so that the embedding vectors for the TF bins dominated by the same speaker are forced to get close to each other. One concern regarding DC is that the embedding process described by a DNN has a black-box structure, which is usually very hard to interpret. The potential weakness owing to the non-interpretable black-box structure is that it lacks the flexibility of addressing the mismatch between training and test conditions (caused by reverberation, for instance). To overcome this limitation, in this paper, we propose the concept of explainable deep clustering (X-DC), whose network architecture can be interpreted as a process of fitting learnable spectrogram templates to an input spectrogram followed by Wiener filtering. During training, the elements of the spectrogram templates and their activations are constrained to be non-negative, which facilitates the sparsity of their values and thus improves interpretability. The main advantage of this framework is that it naturally allows us to incorporate a model adaptation mechanism into the network thanks to its physically interpretable structure. We experimentally show that the proposed X-DC enables us to visualize and understand the clues for the model to determine the embedding vectors while achieving speech separation performance comparable to that of the original DC models.