Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embedding Perturbation for Sentence Classification
Paper and Code
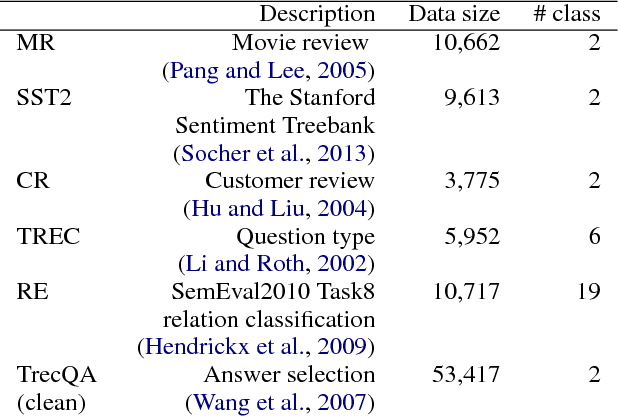
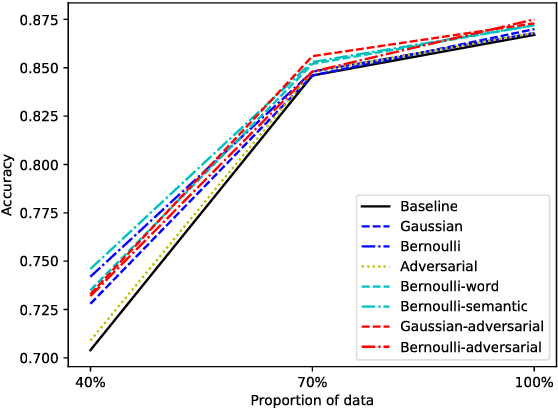
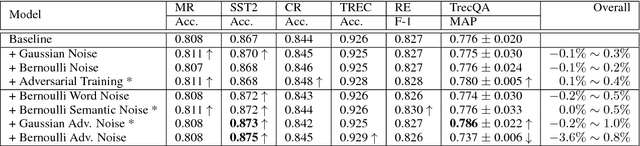
In this technique report, we aim to mitigate the overfitting problem of natural language by applying data augmentation methods. Specifically, we attempt several types of noise to perturb the input word embedding, such as Gaussian noise, Bernoulli noise, and adversarial noise, etc. We also apply several constraints on different types of noise. By implementing these proposed data augmentation methods, the baseline models can gain improvements on several sentence classification tasks.
View paper on