 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embedding for Social Sciences: An Interdisciplinary Survey
Paper and Code
Jul 07, 2022
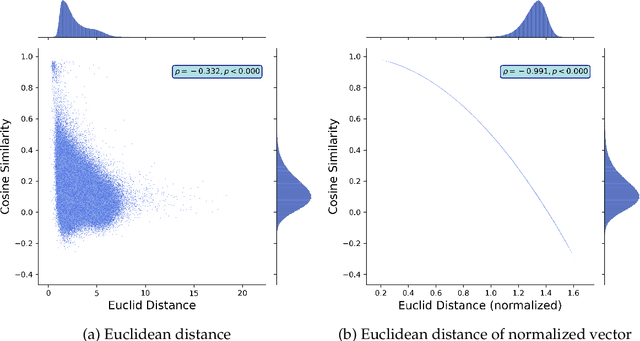
To extract essential information from complex data, computer scientists have been developing machine learning models that learn low-dimensional representation mode. From such advances in machine learning research, not only computer scientists but also social scientists have benefited and advanced their research because human behavior or social phenomena lies in complex data. To document this emerging trend, we survey the recent studies that apply word embedding techniques to human behavior mining, building a taxonomy to illustrate the methods and procedures used in the surveyed papers and highlight the recent emerging trends applying word embedding models to non-textual human behavior data. This survey conducts a simple experiment to warn that common similarity measurements used in the literature could yield different results even if they return consistent results at an aggregate level.