Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill Multi-modal Data Improves Few-shot Learning?
Paper and Code
Jul 25, 2021
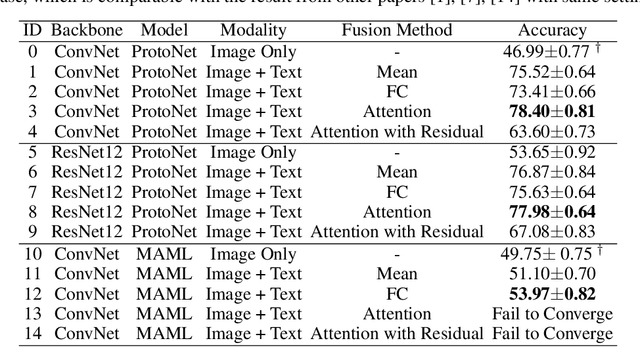
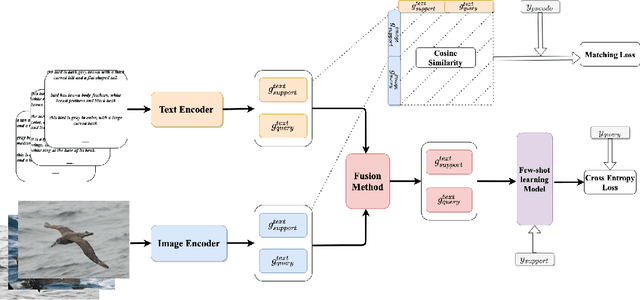

Most few-shot learning models utilize only one modality of data. We would like to investigate qualitatively and quantitatively how much will the model improve if we add an extra modality (i.e. text description of the image), and how it affects the learning procedure. To achieve this goal, we propose four types of fusion method to combine the image feature and text feature. To verify the effectiveness of improvement, we test the fusion methods with two classical few-shot learning models - ProtoNet and MAML, with image feature extractors such as ConvNet and ResNet12. The attention-based fusion method works best, which improves the classification accuracy by a large margin around 30% comparing to the baseline result.
* Project Report
View paper on