 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgewildNeRF: Complete view synthesis of in-the-wild dynamic scenes captured using sparse monocular data
Paper and Code


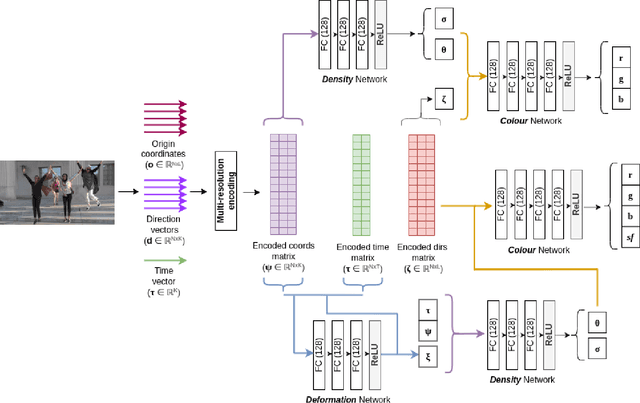
We present a novel neural radiance model that is trainable in a self-supervised manner for novel-view synthesis of dynamic unstructured scenes. Our end-to-end trainable algorithm learns highly complex, real-world static scenes within seconds and dynamic scenes with both rigid and non-rigid motion within minutes. By differentiating between static and motion-centric pixels, we create high-quality representations from a sparse set of images. We perform extensive qualitative and quantitative evaluation on existing benchmarks and set the state-of-the-art on performance measures on the challenging NVIDIA Dynamic Scenes Dataset. Additionally, we evaluate our model performance on challenging real-world datasets such as Cholec80 and SurgicalActions160.