 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidth-Based Planning and Active Learning for Atari
Paper and Code
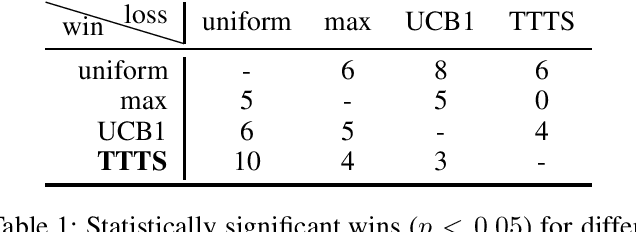
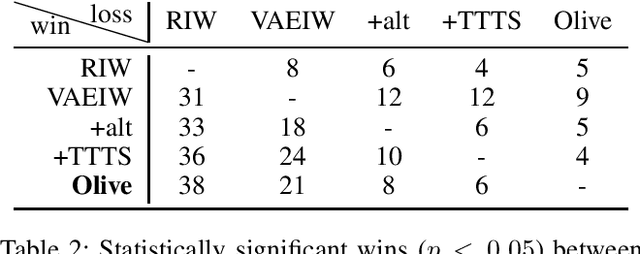
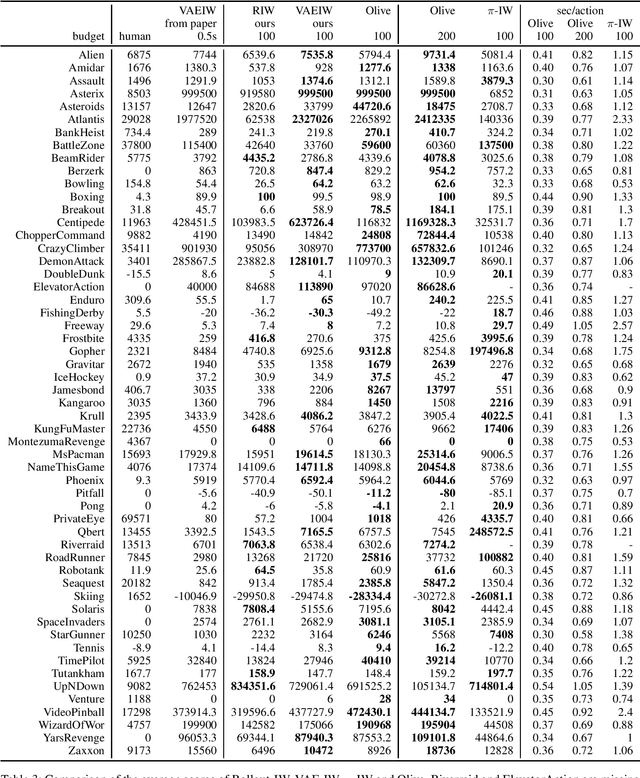
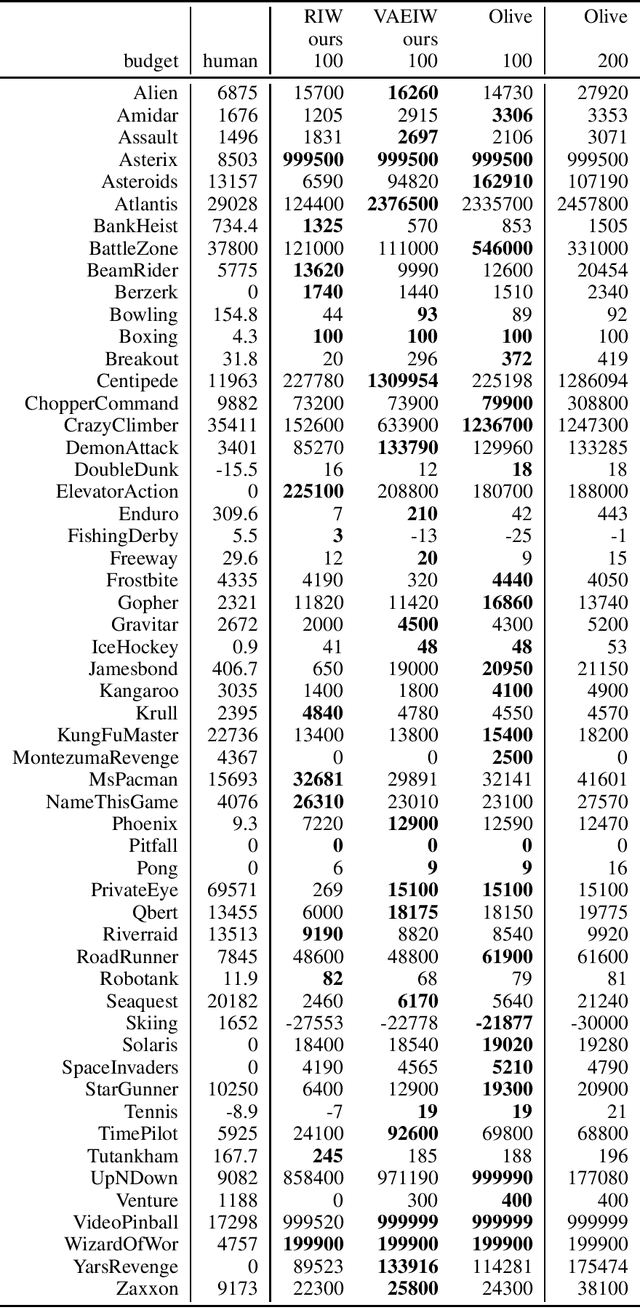
Width-based planning has shown promising results on Atari 2600 games using pixel input, while using substantially fewer environment interactions than reinforcement learning. Recent width-based approaches have computed feature vectors for each screen using a hand designed feature set or a variational autoencoder (VAE) trained on game screens, and prune screens that do not have novel features during the search. In this paper, we explore consideration of uncertainty in features generated by a VAE during width-based planning. Our primary contribution is the introduction of active learning to maximize the utility of screens observed during planning. Experimental results demonstrate that use of active learning strategies increases gameplay scores compared to alternative width-based approaches with equal numbers of environment interactions.