 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide-minima Density Hypothesis and the Explore-Exploit Learning Rate Schedule
Paper and Code
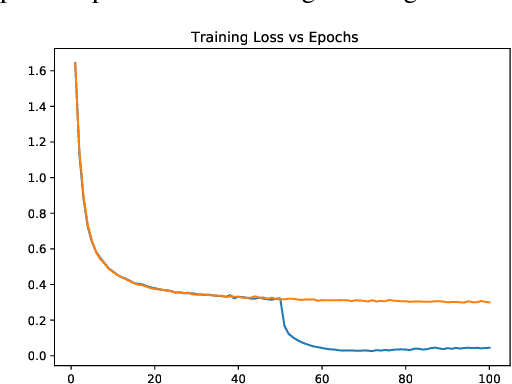
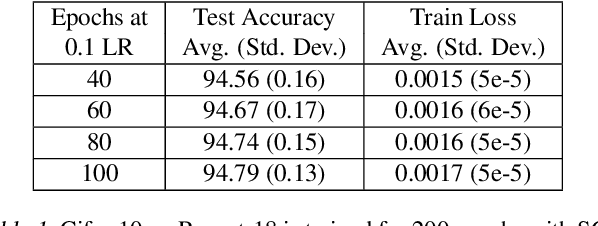
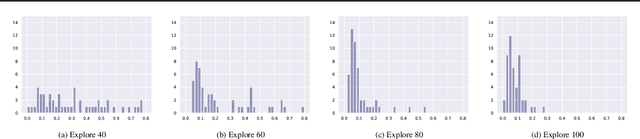
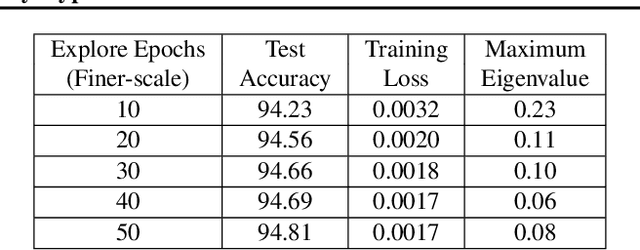
While the generalization properties of neural networks are not yet well understood, several papers argue that wide minima generalize better than narrow minima. In this paper, through detailed experiments that not only corroborate the generalization properties of wide minima, we also provide empirical evidence for a new hypothesis that the density of wide minima is likely lower than the density of narrow minima. Further, motivated by this hypothesis, we design a novel explore-exploit learning rate schedule. On a variety of image and natural language datasets, compared to their original hand-tuned learning rate baselines, we show that our explore-exploit schedule can result in either up to 0.5\% higher absolute accuracy using the original training budget or up to 44\% reduced training time while achieving the original reported accuracy.