 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole page recognition of historical handwriting
Paper and Code
Sep 22, 2020
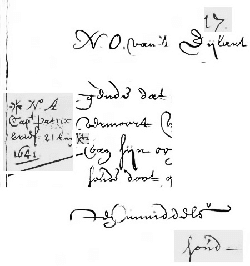
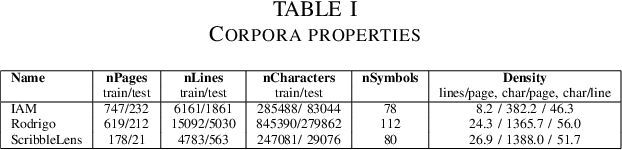
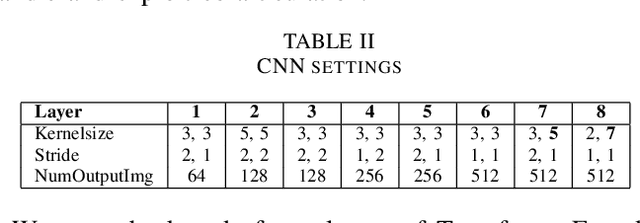
Historical handwritten documents guard an important part of human knowledge only within reach of a few scholars and experts. Recent developments in machine learning and handwriting research have the potential of rendering this information accessible and searchable to a larger audience. To this end, we investigate an end-to-end inference approach without text localization which takes a handwritten page and transcribes its full text. No explicit character, word or line segmentation is involved in inference which is why we call this approach "segmentation free". We explore its robustness and accuracy compared to a line-by-line segmented approach based on the IAM, RODRIGO and ScribbleLens corpora, in three languages with handwriting styles spanning 400 years. We concentrate on model types and sizes which can be deployed on a hand-held or embedded device. We conclude that a whole page inference approach without text localization and segmentation is competitive.