Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen is multitask learning effective? Semantic sequence prediction under varying data conditions
Paper and Code
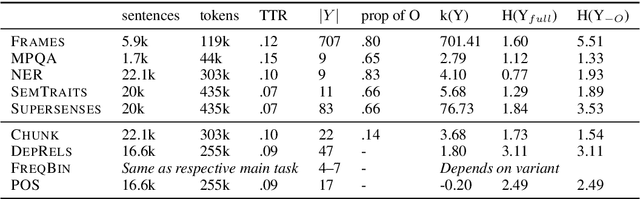
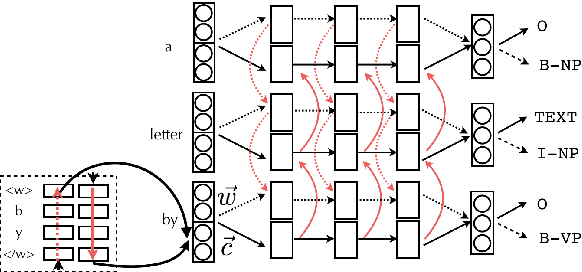


Multitask learning has been applied successfully to a range of tasks, mostly morphosyntactic. However, little is known on when MTL works and whether there are data characteristics that help to determine its success. In this paper we evaluate a range of semantic sequence labeling tasks in a MTL setup. We examine different auxiliary tasks, amongst which a novel setup, and correlate their impact to data-dependent conditions. Our results show that MTL is not always effective, significant improvements are obtained only for 1 out of 5 tasks. When successful, auxiliary tasks with compact and more uniform label distributions are preferable.
* In EACL 2017
View paper on