Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does MAML Work the Best? An Empirical Study on Model-Agnostic Meta-Learning in NLP Applications
Paper and Code
May 24, 2020
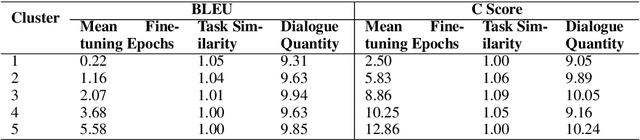
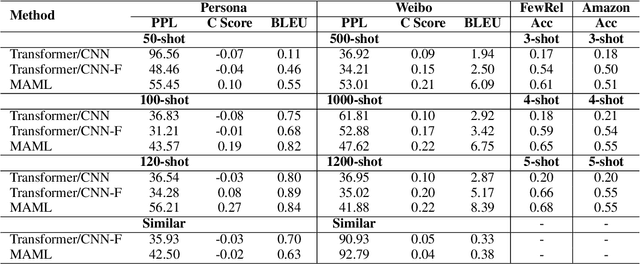
Model-Agnostic Meta-Learning (MAML), a model-agnostic meta-learning method, is successfully employed in NLP applications including few-shot text classification and multi-domain low-resource language generation. Many impacting factors, including data quantity, similarity among tasks, and the balance between general language model and task-specific adaptation, can affect the performance of MAML in NLP, but few works have thoroughly studied them. In this paper, we conduct an empirical study to investigate these impacting factors and conclude when MAML works the best based on the experimental results.
View paper on