 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Measurement? Using GPT-3 on SemEval 2021 Task 8 -- MeasEval
Paper and Code
Jun 28, 2021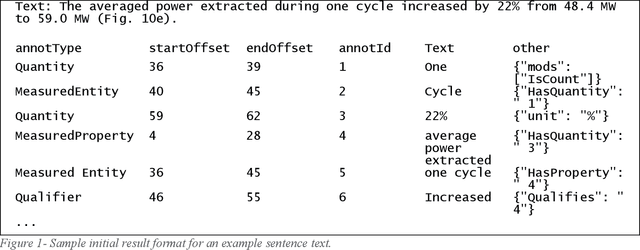



In the summer of 2020 OpenAI released its GPT-3 autoregressive language model to much fanfare. While the model has shown promise on tasks in several areas, it has not always been clear when the results were cherry-picked or when they were the unvarnished output. We were particularly interested in what benefits GPT-3 could bring to the SemEval 2021 MeasEval task - identifying measurements and their associated attributes in scientific literature. We had already experimented with multi-turn questions answering as a solution to this task. We wanted to see if we could use GPT-3's few-shot learning capabilities to more easily develop a solution that would have better performance than our prior work. Unfortunately, we have not been successful in that effort. This paper discusses the approach we used, challenges we encountered, and results we observed. Some of the problems we encountered were simply due to the state of the art. For example, the limits on the size of the prompt and answer limited the amount of the training signal that could be offered. Others are more fundamental. We are unaware of generative models that excel in retaining factual information. Also, the impact of changes in the prompts is unpredictable, making it hard to reliably improve performance.