 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Context Features Can Transformer Language Models Use?
Paper and Code


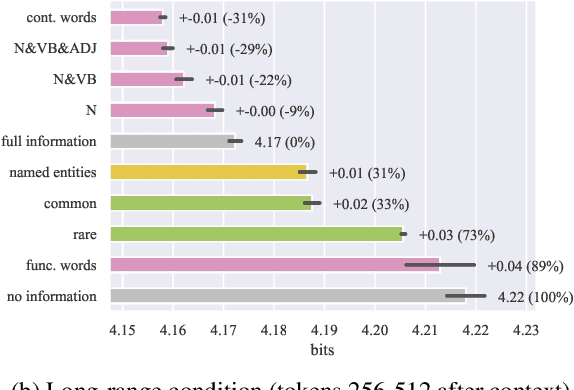
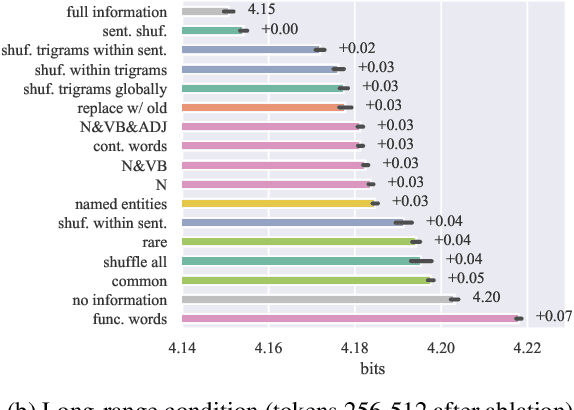
Transformer-based language models benefit from conditioning on contexts of hundreds to thousands of previous tokens. What aspects of these contexts contribute to accurate model prediction? We describe a series of experiments that measure usable information by selectively ablating lexical and structural information in transformer language models trained on English Wikipedia. In both mid- and long-range contexts, we find that several extremely destructive context manipulations -- including shuffling word order within sentences and deleting all words other than nouns -- remove less than 15% of the usable information. Our results suggest that long contexts, but not their detailed syntactic and propositional content, are important for the low perplexity of current transformer language models.