 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWell-Definedness and Efficient Inference for Probabilistic Logic Programming under the Distribution Semantics
Paper and Code
Oct 04, 2011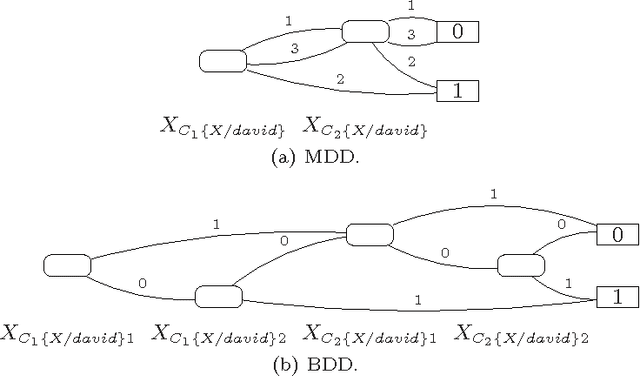
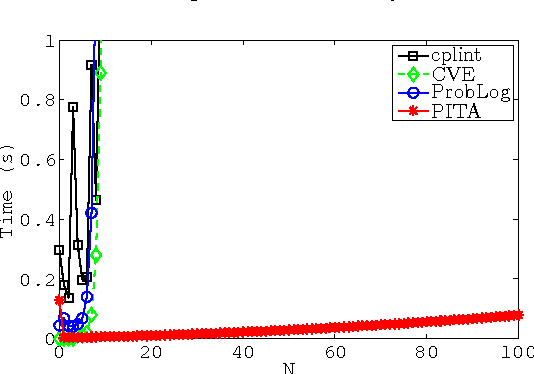
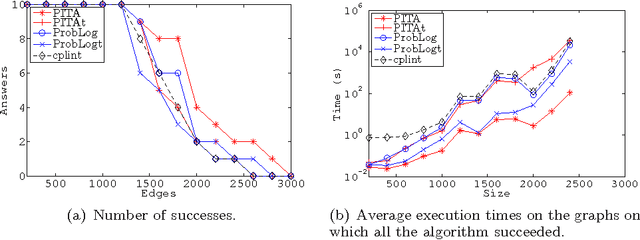
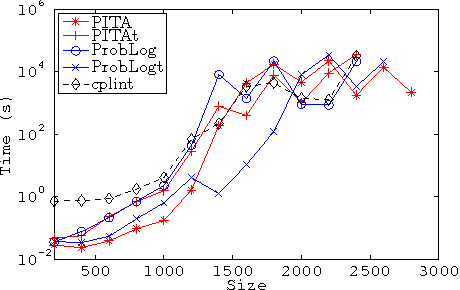
The distribution semantics is one of the most prominent approaches for the combination of logic programming and probability theory. Many languages follow this semantics, such as Independent Choice Logic, PRISM, pD, Logic Programs with Annotated Disjunctions (LPADs) and ProbLog. When a program contains functions symbols, the distribution semantics is well-defined only if the set of explanations for a query is finite and so is each explanation. Well-definedness is usually either explicitly imposed or is achieved by severely limiting the class of allowed programs. In this paper we identify a larger class of programs for which the semantics is well-defined together with an efficient procedure for computing the probability of queries. Since LPADs offer the most general syntax, we present our results for them, but our results are applicable to all languages under the distribution semantics. We present the algorithm "Probabilistic Inference with Tabling and Answer subsumption" (PITA) that computes the probability of queries by transforming a probabilistic program into a normal program and then applying SLG resolution with answer subsumption. PITA has been implemented in XSB and tested on six domains: two with function symbols and four without. The execution times are compared with those of ProbLog, cplint and CVE, PITA was almost always able to solve larger problems in a shorter time, on domains with and without function symbols.