 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighting-Based Treatment Effect Estimation via Distribution Learning
Paper and Code
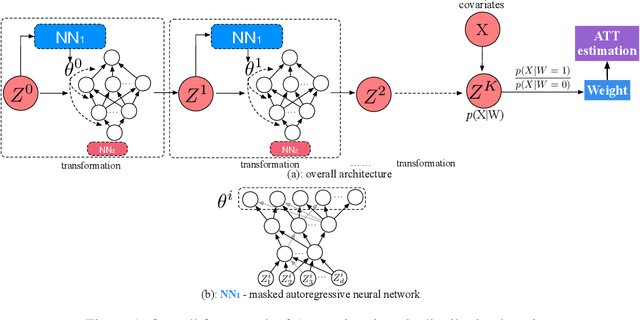
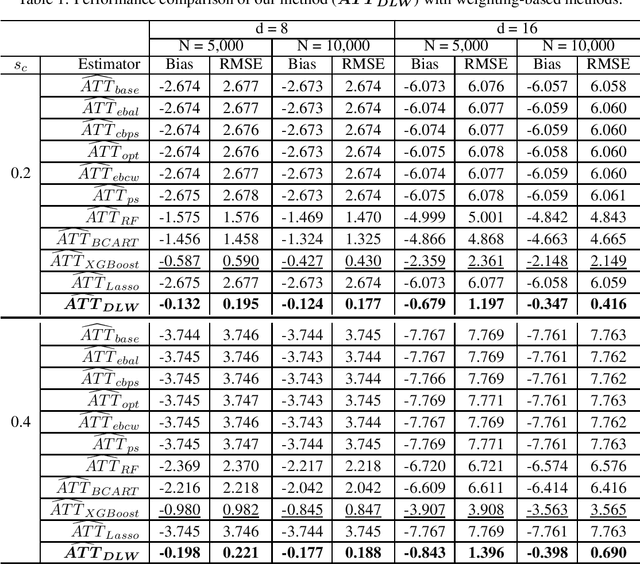


Existing weighting methods for treatment effect estimation are often built upon the idea of propensity scores or covariate balance. They usually impose strong assumptions on treatment assignment or outcome model to obtain unbiased estimation, such as linearity or specific functional forms, which easily leads to the major drawback of model mis-specification. In this paper, we aim to alleviate these issues by developing a distribution learning-based weighting method. We first learn the true underlying distribution of covariates conditioned on treatment assignment, then leverage the ratio of covariates' density in the treatment group to that of the control group as the weight for estimating treatment effects. Specifically, we propose to approximate the distribution of covariates in both treatment and control groups through invertible transformations via change of variables. To demonstrate the superiority, robustness, and generalizability of our method, we conduct extensive experiments using synthetic and real data. From the experiment results, we find that our method for estimating average treatment effect on treated (ATT) with observational data outperforms several cutting-edge weighting-only benchmarking methods, and it maintains its advantage under a doubly-robust estimation framework that combines weighting with some advanced outcome modeling methods.