 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Video Object Grounding from Text by Loss Weighting and Object Interaction
Paper and Code
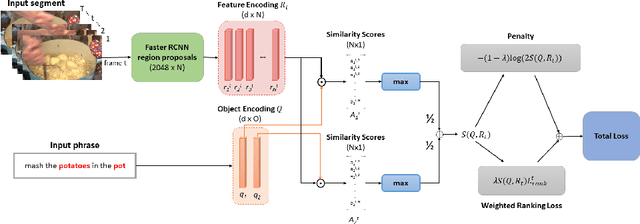
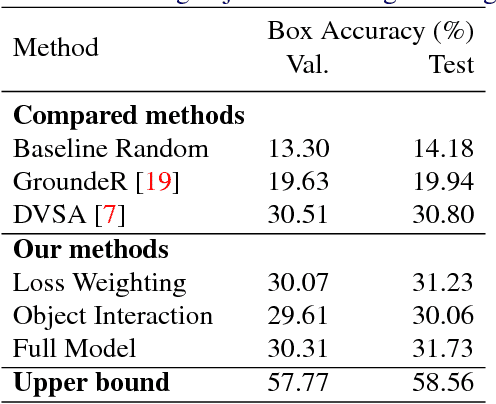
We study weakly-supervised video object grounding: given a video segment and a corresponding descriptive sentence, the goal is to localize objects that are mentioned from the sentence in the video. During training, no object bounding boxes are available, but the set of possible objects to be grounded is known beforehand. Existing approaches in the image domain use Multiple Instance Learning (MIL) to ground objects by enforcing matches between visual and semantic features. A naive extension of this approach to the video domain is to treat the entire segment as a bag of spatial object proposals. However, an object existing sparsely across multiple frames might not be detected completely since successfully spotting it from one single frame would trigger a satisfactory match. To this end, we propagate the weak supervisory signal from the segment level to frames that likely contain the target object. For frames that are unlikely to contain the target objects, we use an alternative penalty loss. We also leverage the interactions among objects as a textual guide for the grounding. We evaluate our model on the newly-collected benchmark YouCook2-BoundingBox and show improvements over competitive baselines.