 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Contrastive Learning for Better Severity Scoring of Lung Ultrasound
Paper and Code
Jan 18, 2022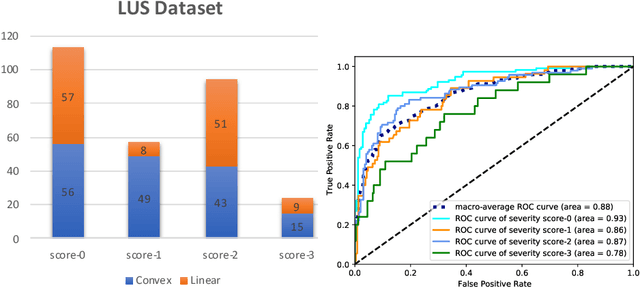
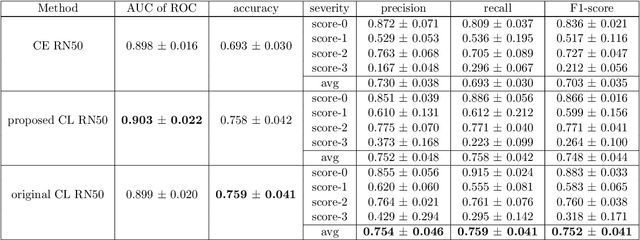
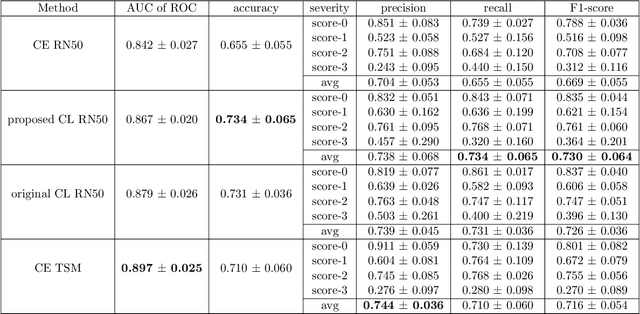
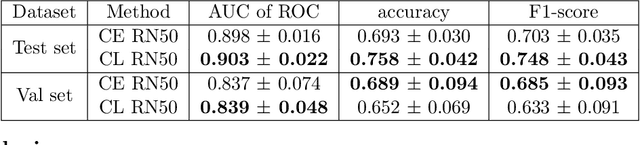
With the onset of the COVID-19 pandemic, ultrasound has emerged as an effective tool for bedside monitoring of patients. Due to this, a large amount of lung ultrasound scans have been made available which can be used for AI based diagnosis and analysis. Several AI-based patient severity scoring models have been proposed that rely on scoring the appearance of the ultrasound scans. AI models are trained using ultrasound-appearance severity scores that are manually labeled based on standardized visual features. We address the challenge of labeling every ultrasound frame in the video clips. Our contrastive learning method treats the video clip severity labels as noisy weak severity labels for individual frames, thus requiring only video-level labels. We show that it performs better than the conventional cross-entropy loss based training. We combine frame severity predictions to come up with video severity predictions and show that the frame based model achieves comparable performance to a video based TSM model, on a large dataset combining public and private sources.