Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWARC-DL: Scalable Web Archive Processing for Deep Learning
Paper and Code
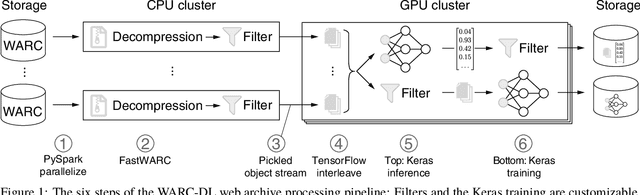
Web archives have grown to petabytes. In addition to providing invaluable background knowledge on many social and cultural developments over the last 30 years, they also provide vast amounts of training data for machine learning. To benefit from recent developments in Deep Learning, the use of web archives requires a scalable solution for their processing that supports inference with and training of neural networks. To date, there is no publicly available library for processing web archives in this way, and some existing applications use workarounds. This paper presents WARC-DL, a deep learning-enabled pipeline for web archive processing that scales to petabytes.
* Submitted to OSSYM 2022 - 4th International Open Search Symposium
View paper on