 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA with no questions-answers training
Paper and Code
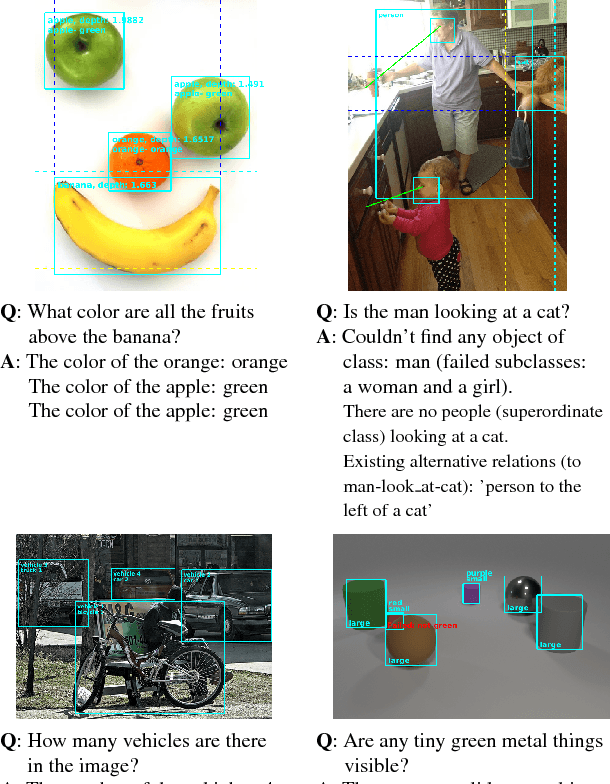
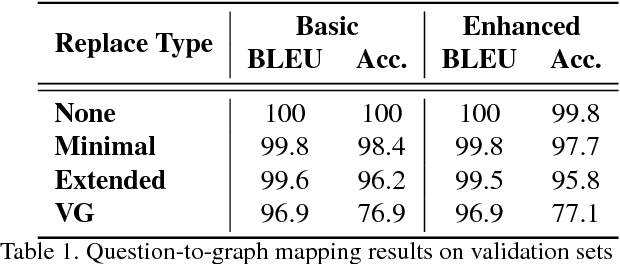

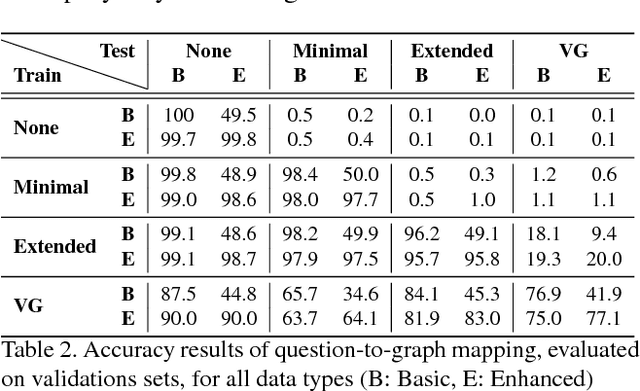
Methods for teaching machines to answer visual questions have made significant progress in the last few years, but although demonstrating impressive results on particular datasets, these methods lack some important human capabilities, including integrating new visual classes and concepts in a modular manner, providing explanations for the answer and handling new domains without new examples. In this paper we present a system that achieves state-of-the-art results on the CLEVR dataset without any questions-answers training, utilizes real visual estimators and explains the answer. The system includes a question representation stage followed by an answering procedure, which invokes an extendable set of visual estimators. It can explain the answer, including its failures, and provide alternatives to negative answers. The scheme builds upon a framework proposed recently, with extensions allowing the system to deal with novel domains without relying on training examples.