 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLCounter: Text-aware Visual Representation for Zero-Shot Object Counting
Paper and Code
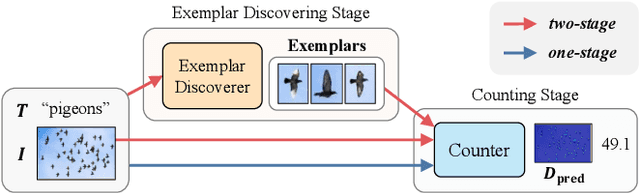
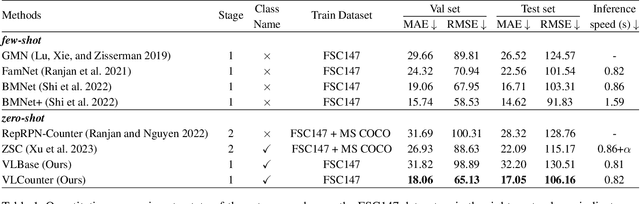
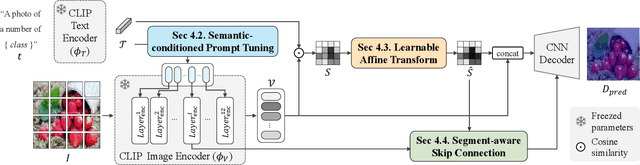
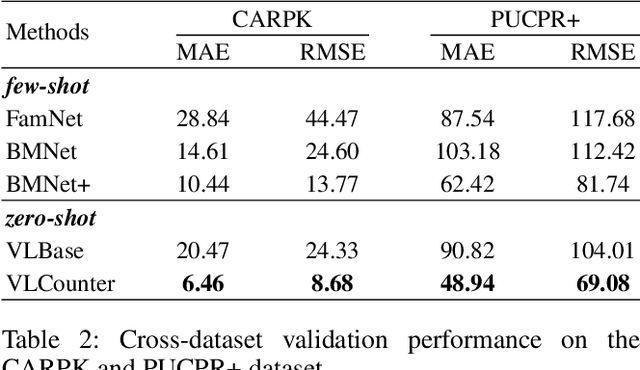
Zero-Shot Object Counting (ZSOC) aims to count referred instances of arbitrary classes in a query image without human-annotated exemplars. To deal with ZSOC, preceding studies proposed a two-stage pipeline: discovering exemplars and counting. However, there remains a challenge of vulnerability to error propagation of the sequentially designed two-stage process. In this work, an one-stage baseline, Visual-Language Baseline (VLBase), exploring the implicit association of the semantic-patch embeddings of CLIP is proposed. Subsequently, the extension of VLBase to Visual-language Counter (VLCounter) is achieved by incorporating three modules devised to tailor VLBase for object counting. First, Semantic-conditioned Prompt Tuning (SPT) is introduced within the image encoder to acquire target-highlighted representations. Second, Learnable Affine Transformation (LAT) is employed to translate the semantic-patch similarity map to be appropriate for the counting task. Lastly, the layer-wisely encoded features are transferred to the decoder through Segment-aware Skip Connection (SaSC) to keep the generalization capability for unseen classes. Through extensive experiments on FSC147, CARPK, and PUCPR+, the benefits of the end-to-end framework, VLCounter, are demonstrated.