 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing high-dimensional loss landscapes with Hessian directions
Paper and Code
Aug 28, 2022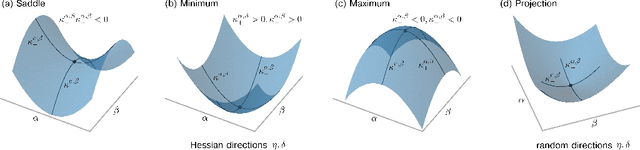
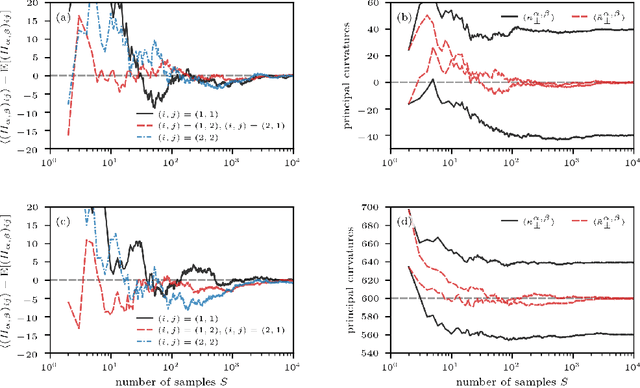
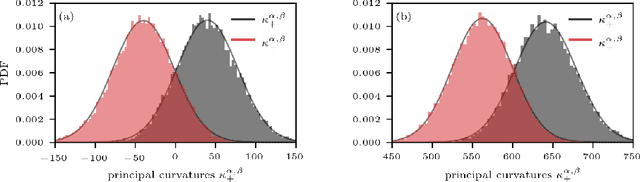
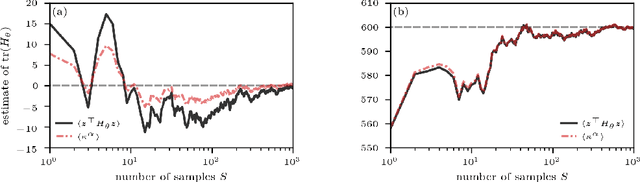
Analyzing geometric properties of high-dimensional loss functions, such as local curvature and the existence of other optima around a certain point in loss space, can help provide a better understanding of the interplay between neural network structure, implementation attributes, and learning performance. In this work, we combine concepts from high-dimensional probability and differential geometry to study how curvature properties in lower-dimensional loss representations depend on those in the original loss space. We show that saddle points in the original space are rarely correctly identified as such in lower-dimensional representations if random projections are used. In such projections, the expected curvature in a lower-dimensional representation is proportional to the mean curvature in the original loss space. Hence, the mean curvature in the original loss space determines if saddle points appear, on average, as either minima, maxima, or almost flat regions. We use the connection between expected curvature and mean curvature (i.e., the normalized Hessian trace) to estimate the trace of Hessians without calculating the Hessian or Hessian-vector products as in Hutchinson's method. Because random projections are not able to correctly identify saddle information, we propose to study projections along Hessian directions that are associated with the largest and smallest principal curvatures. We connect our findings to the ongoing debate on loss landscape flatness and generalizability. Finally, we illustrate our method in numerical experiments on different image classifiers with up to about $7\times 10^6$ parameters.