 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformers with Mixed-Resolution Tokenization
Paper and Code

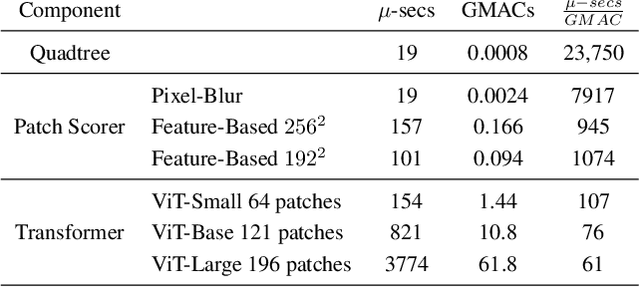


Vision Transformer models process input images by dividing them into a spatially regular grid of equal-size patches. Conversely, Transformers were originally introduced over natural language sequences, where each token represents a subword - a chunk of raw data of arbitrary size. In this work, we apply this approach to Vision Transformers by introducing a novel image tokenization scheme, replacing the standard uniform grid with a mixed-resolution sequence of tokens, where each token represents a patch of arbitrary size. Using the Quadtree algorithm and a novel saliency scorer, we construct a patch mosaic where low-saliency areas of the image are processed in low resolution, routing more of the model's capacity to important image regions. Using the same architecture as vanilla ViTs, our Quadformer models achieve substantial accuracy gains on image classification when controlling for the computational budget. Code and models are publicly available at https://github.com/TomerRonen34/mixed-resolution-vit .