 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer with Convolutional Encoder-Decoder for Hand Gesture Recognition using 24 GHz Doppler Radar
Paper and Code
Sep 12, 2022
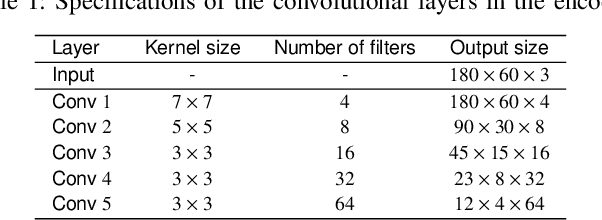
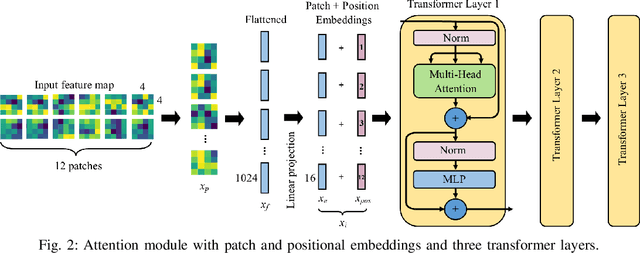
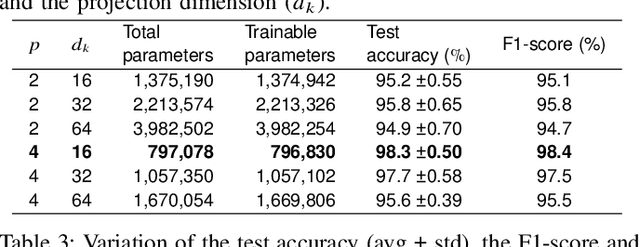
Transformers combined with convolutional encoders have been recently used for hand gesture recognition (HGR) using micro-Doppler signatures. We propose a vision-transformer-based architecture for HGR with multi-antenna continuous-wave Doppler radar receivers. The proposed architecture consists of three modules: a convolutional encoderdecoder, an attention module with three transformer layers, and a multi-layer perceptron. The novel convolutional decoder helps to feed patches with larger sizes to the attention module for improved feature extraction. Experimental results obtained with a dataset corresponding to a two-antenna continuous-wave Doppler radar receiver operating at 24 GHz (published by Skaria et al.) confirm that the proposed architecture achieves an accuracy of 98.3% which substantially surpasses the state-of-the-art on the used dataset.