 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
Paper and Code


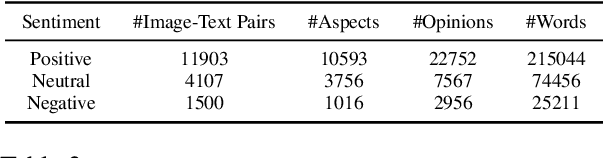
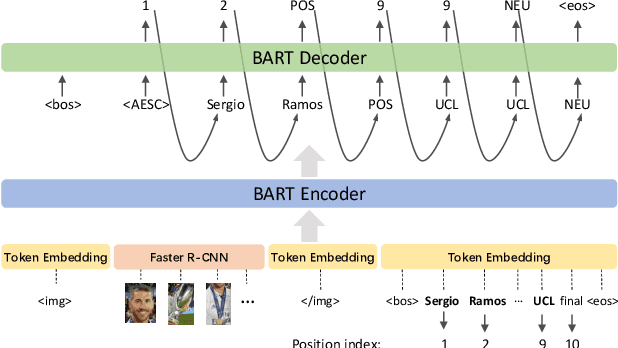
As an important task in sentiment analysis, Multimodal Aspect-Based Sentiment Analysis (MABSA) has attracted increasing attention in recent years. However, previous approaches either (i) use separately pre-trained visual and textual models, which ignore the crossmodal alignment or (ii) use vision-language models pre-trained with general pre-training tasks, which are inadequate to identify finegrained aspects, opinions, and their alignments across modalities. To tackle these limitations, we propose a task-specific Vision-Language Pre-training framework for MABSA (VLPMABSA), which is a unified multimodal encoder-decoder architecture for all the pretraining and downstream tasks. We further design three types of task-specific pre-training tasks from the language, vision, and multimodal modalities, respectively. Experimental results show that our approach generally outperforms the state-of-the-art approaches on three MABSA subtasks. Further analysis demonstrates the effectiveness of each pretraining task. The source code is publicly released at https://github.com/NUSTM/VLP-MABSA.