 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo SemNet: Memory-Augmented Video Semantic Network
Paper and Code
Nov 22, 2020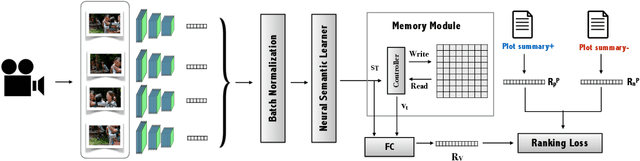
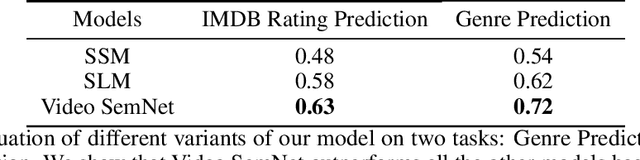
Stories are a very compelling medium to convey ideas, experiences, social and cultural values. Narrative is a specific manifestation of the story that turns it into knowledge for the audience. In this paper, we propose a machine learning approach to capture the narrative elements in movies by bridging the gap between the low-level data representations and semantic aspects of the visual medium. We present a Memory-Augmented Video Semantic Network, called Video SemNet, to encode the semantic descriptors and learn an embedding for the video. The model employs two main components: (i) a neural semantic learner that learns latent embeddings of semantic descriptors and (ii) a memory module that retains and memorizes specific semantic patterns from the video. We evaluate the video representations obtained from variants of our model on two tasks: (a) genre prediction and (b) IMDB Rating prediction. We demonstrate that our model is able to predict genres and IMDB ratings with a weighted F-1 score of 0.72 and 0.63 respectively. The results are indicative of the representational power of our model and the ability of such representations to measure audience engagement.