 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo captioning with recurrent networks based on frame- and video-level features and visual content classification
Paper and Code
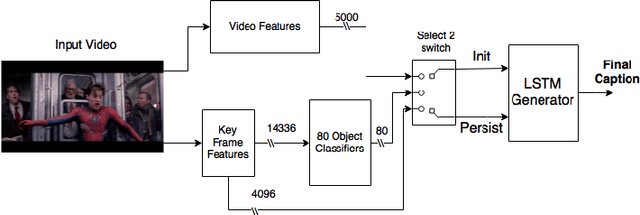
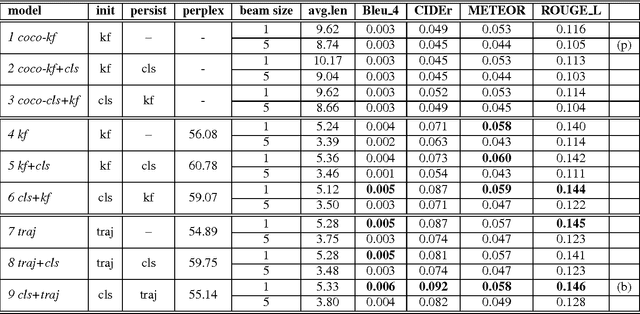
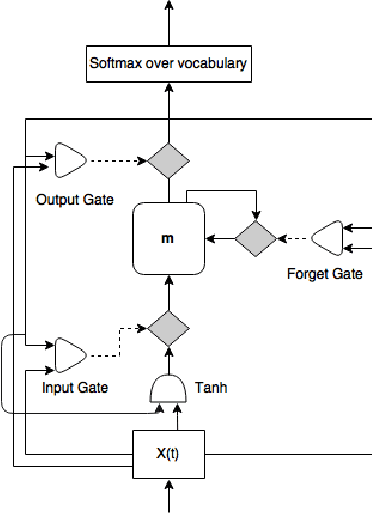
In this paper, we describe the system for generating textual descriptions of short video clips using recurrent neural networks (RNN), which we used while participating in the Large Scale Movie Description Challenge 2015 in ICCV 2015. Our work builds on static image captioning systems with RNN based language models and extends this framework to videos utilizing both static image features and video-specific features. In addition, we study the usefulness of visual content classifiers as a source of additional information for caption generation. With experimental results we show that utilizing keyframe based features, dense trajectory video features and content classifier outputs together gives better performance than any one of them individually.