Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Action Classification Using PredNet
Paper and Code
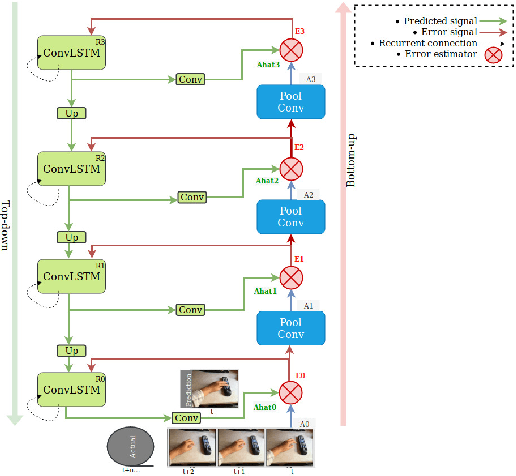
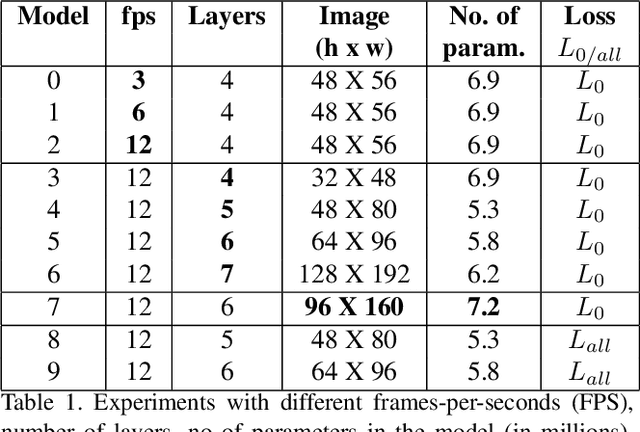
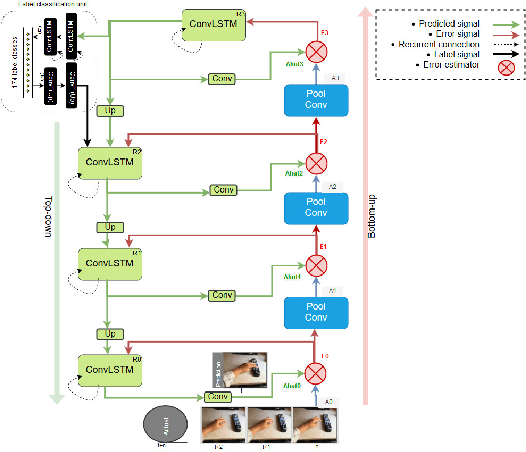

In this paper, we evaluate the PredNet \cite{lotter16} on the Something-something action data set \cite{farzaneh18} and implement the PredNet+, which we train in a multi-task fashion to output both classification labels and predictions. Our idea is to condition video prediction and action classification on each other. We discuss a series of observations about the PredNet and conclude that it does not completely follow the principles of the predictive coding framework.
View paper on