 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVertex Feature Encoding and Hierarchical Temporal Modeling in a Spatial-Temporal Graph Convolutional Network for Action Recognition
Paper and Code
Dec 20, 2019
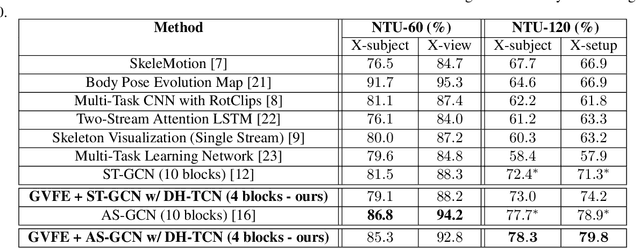
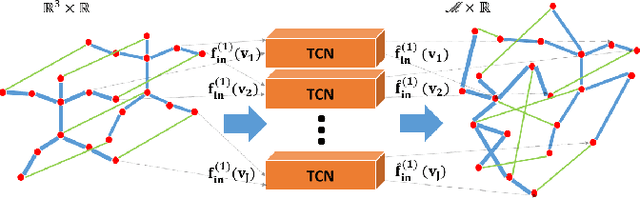

This paper extends the Spatial-Temporal Graph Convolutional Network (ST-GCN) for skeleton-based action recognition by introducing two novel modules, namely, the Graph Vertex Feature Encoder (GVFE) and the Dilated Hierarchical Temporal Convolutional Network (DH-TCN). On the one hand, the GVFE module learns appropriate vertex features for action recognition by encoding raw skeleton data into a new feature space. On the other hand, the DH-TCN module is capable of capturing both short-term and long-term temporal dependencies using a hierarchical dilated convolutional network. Experiments have been conducted on the challenging NTU RGB-D-60 and NTU RGB-D 120 datasets. The obtained results show that our method competes with state-of-the-art approaches while using a smaller number of layers and parameters; thus reducing the required training time and memory.