 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifying Quantized Neural Networks using SMT-Based Model Checking
Paper and Code
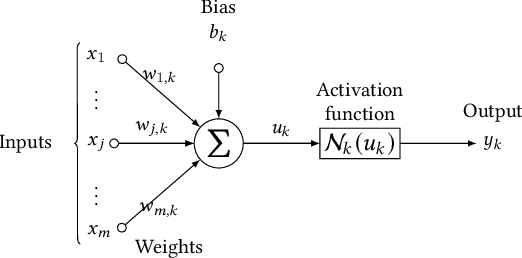
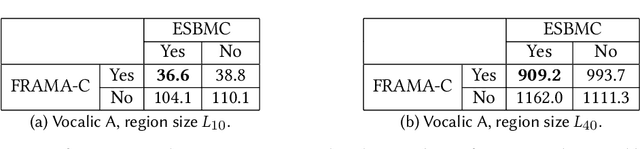
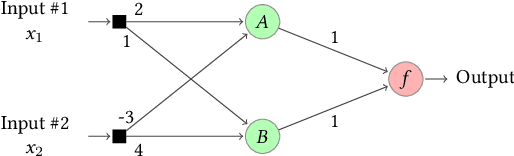
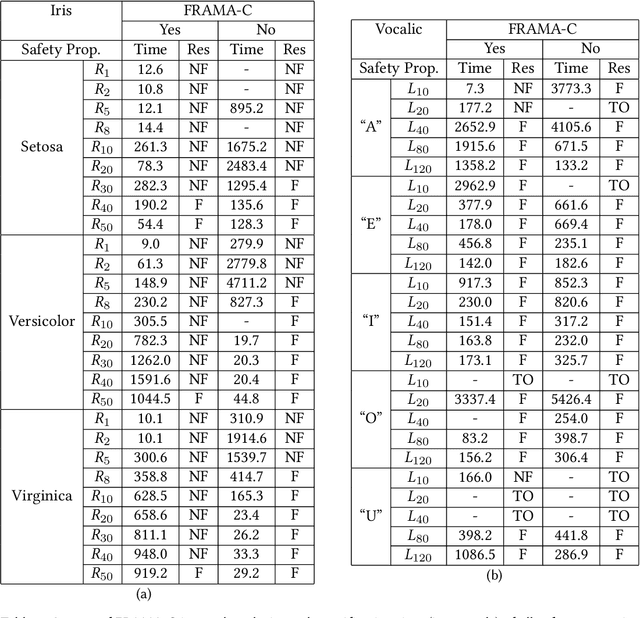
Artificial Neural Networks (ANNs) are being deployed on an increasing number of safety-critical applications, including autonomous cars and medical diagnosis. However, concerns about their reliability have been raised due to their black-box nature and apparent fragility to adversarial attacks. Here, we develop and evaluate a symbolic verification framework using incremental model checking (IMC) and satisfiability modulo theories (SMT) to check for vulnerabilities in ANNs. More specifically, we propose several ANN-related optimizations for IMC, including invariant inference via interval analysis and the discretization of non-linear activation functions. With this, we can provide guarantees on the safe behavior of ANNs implemented both in floating-point and fixed-point (quantized) arithmetic. In this regard, our verification approach was able to verify and produce adversarial examples for 52 test cases spanning image classification and general machine learning applications. For small- to medium-sized ANN, our approach completes most of its verification runs in minutes. Moreover, in contrast to most state-of-the-art methods, our approach is not restricted to specific choices of activation functions or non-quantized representations.