 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector-Quantized Timbre Representation
Paper and Code
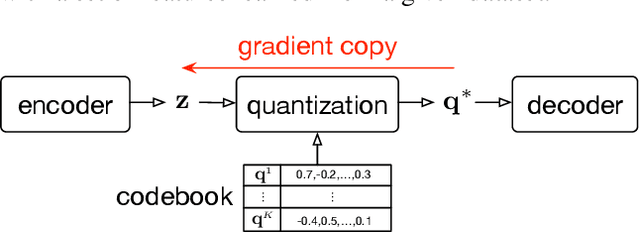
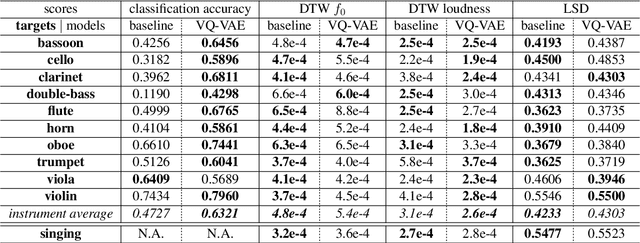

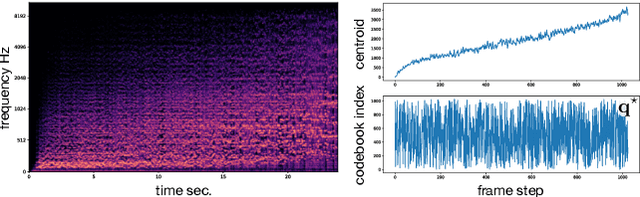
Timbre is a set of perceptual attributes that identifies different types of sound sources. Although its definition is usually elusive, it can be seen from a signal processing viewpoint as all the spectral features that are perceived independently from pitch and loudness. Some works have studied high-level timbre synthesis by analyzing the feature relationships of different instruments, but acoustic properties remain entangled and generation bound to individual sounds. This paper targets a more flexible synthesis of an individual timbre by learning an approximate decomposition of its spectral properties with a set of generative features. We introduce an auto-encoder with a discrete latent space that is disentangled from loudness in order to learn a quantized representation of a given timbre distribution. Timbre transfer can be performed by encoding any variable-length input signals into the quantized latent features that are decoded according to the learned timbre. We detail results for translating audio between orchestral instruments and singing voice, as well as transfers from vocal imitations to instruments as an intuitive modality to drive sound synthesis. Furthermore, we can map the discrete latent space to acoustic descriptors and directly perform descriptor-based synthesis.