 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Option Discovery Algorithms
Paper and Code
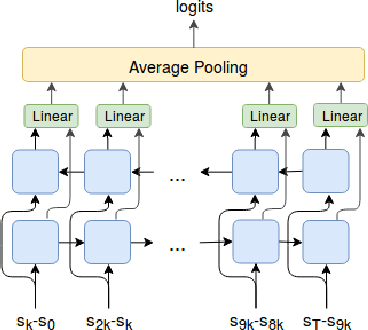
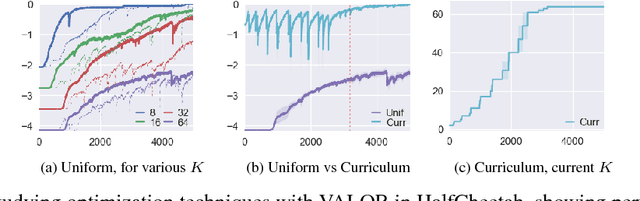
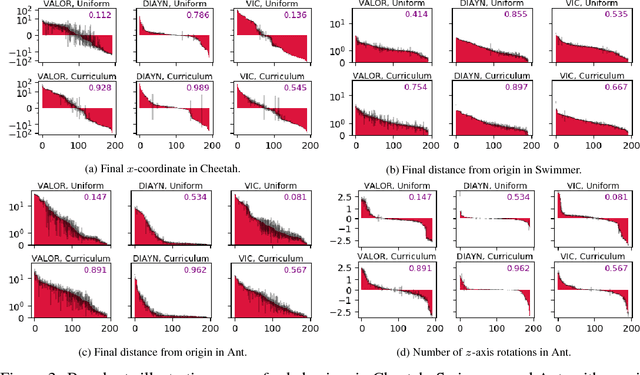
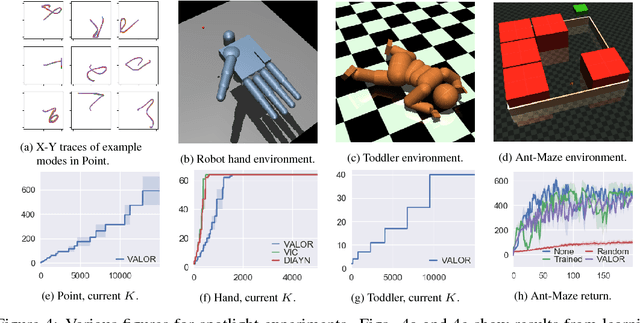
We explore methods for option discovery based on variational inference and make two algorithmic contributions. First: we highlight a tight connection between variational option discovery methods and variational autoencoders, and introduce Variational Autoencoding Learning of Options by Reinforcement (VALOR), a new method derived from the connection. In VALOR, the policy encodes contexts from a noise distribution into trajectories, and the decoder recovers the contexts from the complete trajectories. Second: we propose a curriculum learning approach where the number of contexts seen by the agent increases whenever the agent's performance is strong enough (as measured by the decoder) on the current set of contexts. We show that this simple trick stabilizes training for VALOR and prior variational option discovery methods, allowing a single agent to learn many more modes of behavior than it could with a fixed context distribution. Finally, we investigate other topics related to variational option discovery, including fundamental limitations of the general approach and the applicability of learned options to downstream tasks.