 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Reduced Cascade Q-learning: Algorithms and Sample Complexity
Paper and Code
Aug 13, 2024

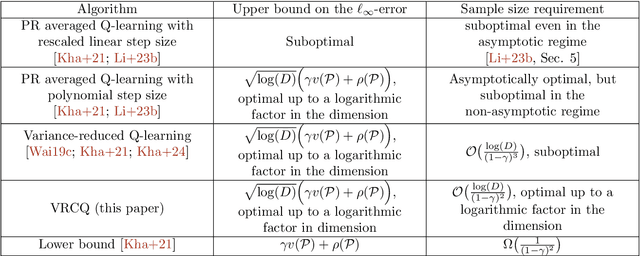

We study the problem of estimating the optimal Q-function of $\gamma$-discounted Markov decision processes (MDPs) under the synchronous setting, where independent samples for all state-action pairs are drawn from a generative model at each iteration. We introduce and analyze a novel model-free algorithm called Variance-Reduced Cascade Q-learning (VRCQ). VRCQ comprises two key building blocks: (i) the established direct variance reduction technique and (ii) our proposed variance reduction scheme, Cascade Q-learning. By leveraging these techniques, VRCQ provides superior guarantees in the $\ell_\infty$-norm compared with the existing model-free stochastic approximation-type algorithms. Specifically, we demonstrate that VRCQ is minimax optimal. Additionally, when the action set is a singleton (so that the Q-learning problem reduces to policy evaluation), it achieves non-asymptotic instance optimality while requiring the minimum number of samples theoretically possible. Our theoretical results and their practical implications are supported by numerical experiments.