 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Instance-Level Explainability for Text Classification
Paper and Code


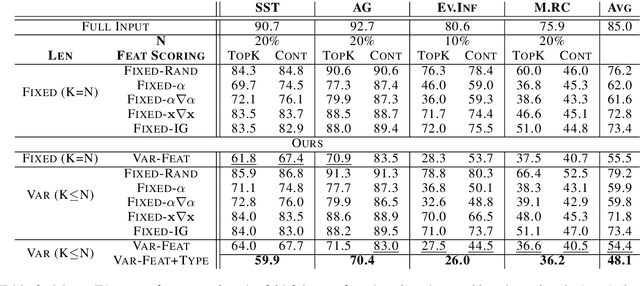
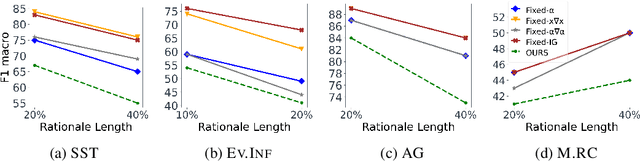
Despite the high accuracy of pretrained transformer networks in text classification, a persisting issue is their significant complexity that makes them hard to interpret. Recent research has focused on developing feature scoring methods for identifying which parts of the input are most important for the model to make a particular prediction and use it as an explanation (i.e. rationale). A limitation of these approaches is that they assume that a particular feature scoring method should be used across all instances in a dataset using a predefined fixed length, which might not be optimal across all instances. To address this, we propose a method for extracting variable-length explanations using a set of different feature scoring methods at instance-level. Our method is inspired by word erasure approaches which assume that the most faithful rationale for a prediction should be the one with the highest divergence between the model's output distribution using the full text and the text after removing the rationale for a particular instance. Evaluation on four standard text classification datasets shows that our method consistently provides more faithful explanations compared to previous fixed-length and fixed-feature scoring methods for rationale extraction.