 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtterance-level Sequential Modeling For Deep Gaussian Process Based Speech Synthesis Using Simple Recurrent Unit
Paper and Code
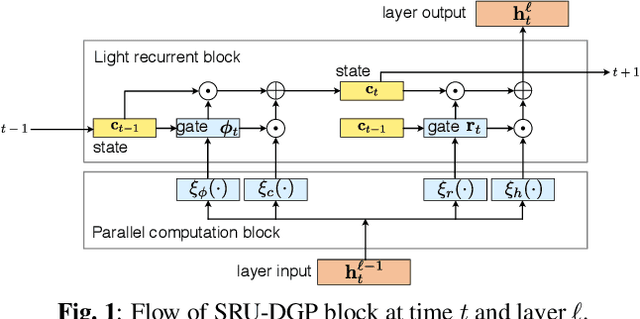
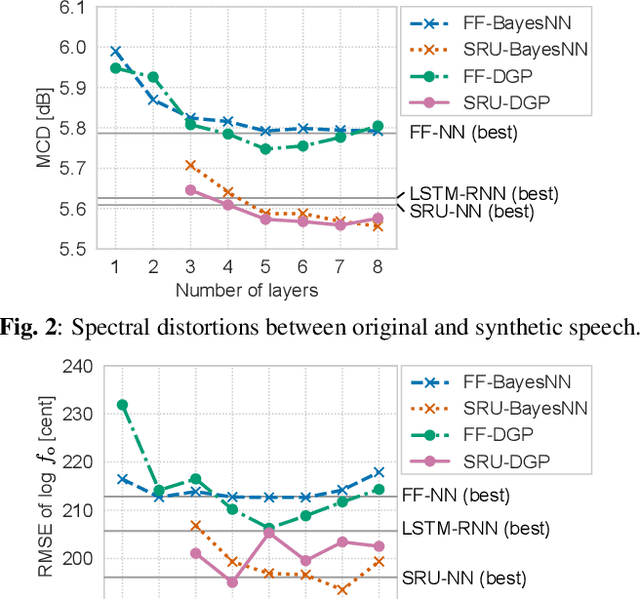
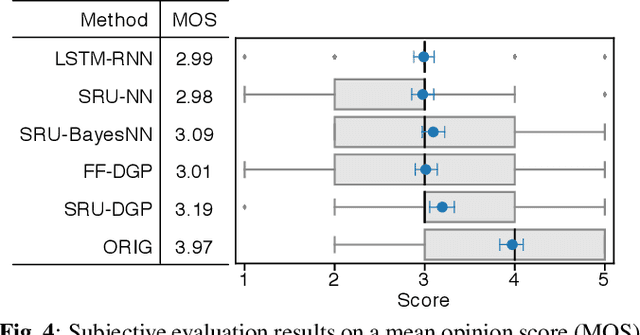
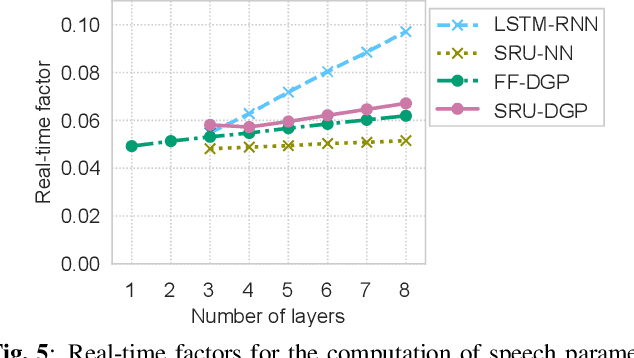
This paper presents a deep Gaussian process (DGP) model with a recurrent architecture for speech sequence modeling. DGP is a Bayesian deep model that can be trained effectively with the consideration of model complexity and is a kernel regression model that can have high expressibility. In the previous studies, it was shown that the DGP-based speech synthesis outperformed neural network-based one, in which both models used a feed-forward architecture. To improve the naturalness of synthetic speech, in this paper, we show that DGP can be applied to utterance-level modeling using recurrent architecture models. We adopt a simple recurrent unit (SRU) for the proposed model to achieve a recurrent architecture, in which we can execute fast speech parameter generation by using the high parallelization nature of SRU. The objective and subjective evaluation results show that the proposed SRU-DGP-based speech synthesis outperforms not only feed-forward DGP but also automatically tuned SRU- and long short-term memory (LSTM)-based neural networks.